 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferred Discrepancy: Quantifying the Difference Between Representations
Paper and Code
Jul 24, 2020

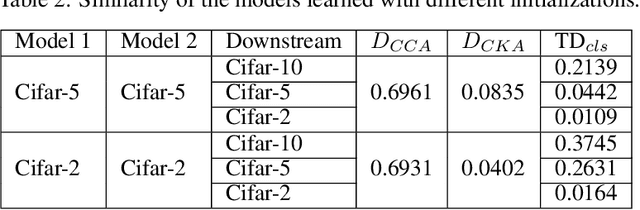

Understanding what information neural networks capture is an essential problem in deep learning, and studying whether different models capture similar features is an initial step to achieve this goal. Previous works sought to define metrics over the feature matrices to measure the difference between two models. However, different metrics sometimes lead to contradictory conclusions, and there has been no consensus on which metric is suitable to use in practice. In this work, we propose a novel metric that goes beyond previous approaches. Recall that one of the most practical scenarios of using the learned representations is to apply them to downstream tasks. We argue that we should design the metric based on a similar principle. For that, we introduce the transferred discrepancy (TD), a new metric that defines the difference between two representations based on their downstream-task performance. Through an asymptotic analysis, we show how TD correlates with downstream tasks and the necessity to define metrics in such a task-dependent fashion. In particular, we also show that under specific conditions, the TD metric is closely related to previous metrics. Our experiments show that TD can provide fine-grained information for varied downstream tasks, and for the models trained from different initializations, the learned features are not the same in terms of downstream-task predictions. We find that TD may also be used to evaluate the effectiveness of different training strategies. For example, we demonstrate that the models trained with proper data augmentations that improve the generalization capture more similar features in terms of TD, while those with data augmentations that hurt the generalization will not. This suggests a training strategy that leads to more robust representation also trains models that generalize better.