 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransductive few-shot adapters for medical image segmentation
Paper and Code

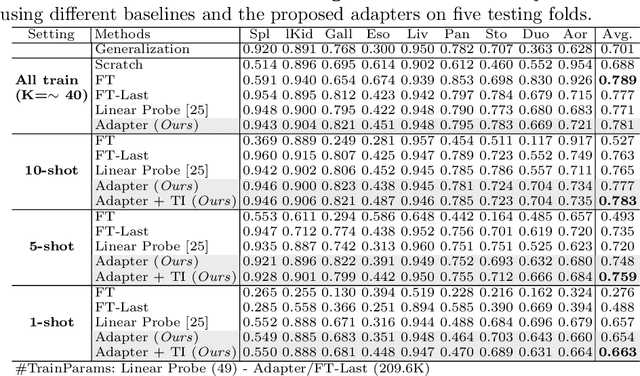


With the recent raise of foundation models in computer vision and NLP, the pretrain-and-adapt strategy, where a large-scale model is fine-tuned on downstream tasks, is gaining popularity. However, traditional fine-tuning approaches may still require significant resources and yield sub-optimal results when the labeled data of the target task is scarce. This is especially the case in clinical settings. To address this challenge, we formalize few-shot efficient fine-tuning (FSEFT), a novel and realistic setting for medical image segmentation. Furthermore, we introduce a novel parameter-efficient fine-tuning strategy tailored to medical image segmentation, with (a) spatial adapter modules that are more appropriate for dense prediction tasks; and (b) a constrained transductive inference, which leverages task-specific prior knowledge. Our comprehensive experiments on a collection of public CT datasets for organ segmentation reveal the limitations of standard fine-tuning methods in few-shot scenarios, point to the potential of vision adapters and transductive inference, and confirm the suitability of foundation models.