 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Neural Networks in Near-Linear Time
Paper and Code
Jun 20, 2020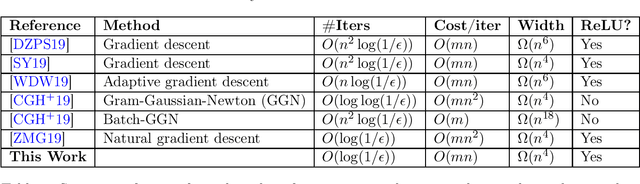
The slow convergence rate and pathological curvature issues of first-order gradient methods for training deep neural networks, initiated an ongoing effort for developing faster $\mathit{second}$-$\mathit{order}$ optimization algorithms beyond SGD, without compromising the generalization error. Despite their remarkable convergence rate ($\mathit{independent}$ of the training batch size $n$), second-order algorithms incur a daunting slowdown in the $\mathit{cost}$ $\mathit{per}$ $\mathit{iteration}$ (inverting the Hessian matrix of the loss function), which renders them impractical. Very recently, this computational overhead was mitigated by the works of [ZMG19, CGH+19], yielding an $O(Mn^2)$-time second-order algorithm for training overparametrized neural networks with $M$ parameters. We show how to speed up the algorithm of [CGH+19], achieving an $\tilde{O}(Mn)$-time backpropagation algorithm for training (mildly overparametrized) ReLU networks, which is near-linear in the dimension ($Mn$) of the full gradient (Jacobian) matrix. The centerpiece of our algorithm is to reformulate the Gauss-Newton iteration as an $\ell_2$-regression problem, and then use a Fast-JL type dimension reduction to $\mathit{precondition} $ the underlying Gram matrix in time independent of $M$, allowing to find a sufficiently good approximate solution via $\mathit{first}$-$\mathit{order}$ conjugate gradient. Our result provides a proof-of-concept that advanced machinery from randomized linear algebra-which led to recent breakthroughs in $\mathit{convex}$ $\mathit{optimization}$ (ERM, LPs, Regression)-can be carried over to the realm of deep learning as well.