 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Deep Neural Networks with Joint Quantization and Pruning of Weights and Activations
Paper and Code
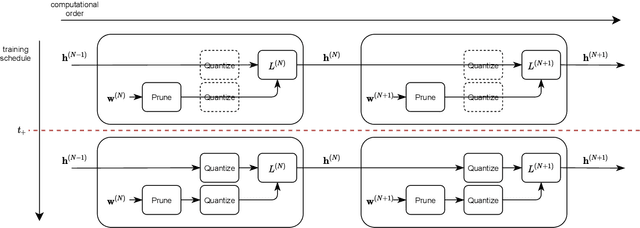
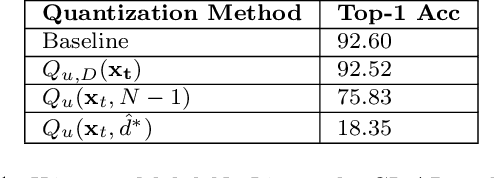
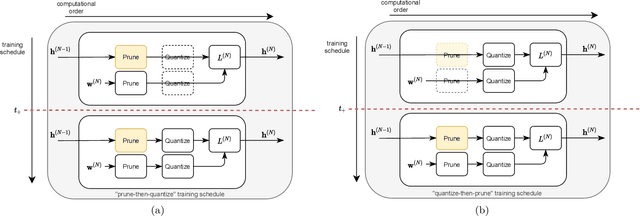

Quantization and pruning are core techniques used to reduce the inference costs of deep neural networks. State-of-the-art quantization techniques are currently applied to both the weights and activations; however, pruning is most often applied to only the weights of the network. In this work, we jointly apply novel uniform quantization and unstructured pruning methods to both the weights and activations of deep neural networks during training. Using our methods, we empirically evaluate the currently accepted prune-then-quantize paradigm across a wide range of computer vision tasks and observe a non-commutative nature when applied to both the weights and activations of deep neural networks. Informed by these observations, we articulate the non-commutativity hypothesis: for a given deep neural network being trained for a specific task, there exists an exact training schedule in which quantization and pruning can be introduced to optimize network performance. We identify that this optimal ordering not only exists, but also varies across discriminative and generative tasks. Using the optimal training schedule within our training framework, we demonstrate increased performance per memory footprint over existing solutions.