 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards the Mitigation of Confirmation Bias in Semi-supervised Learning: a Debiased Training Perspective
Paper and Code
Sep 26, 2024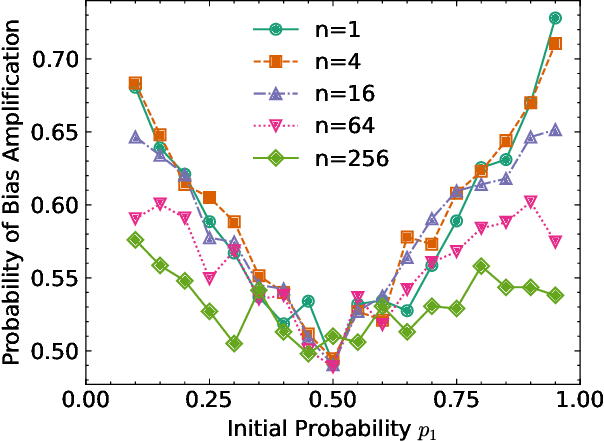
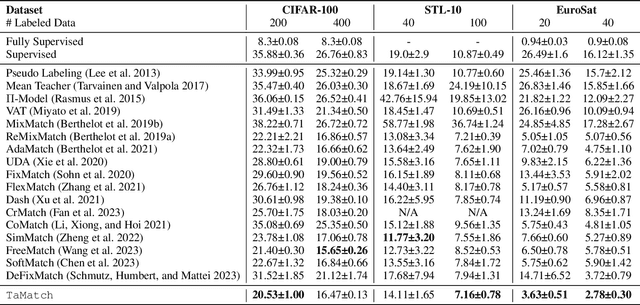
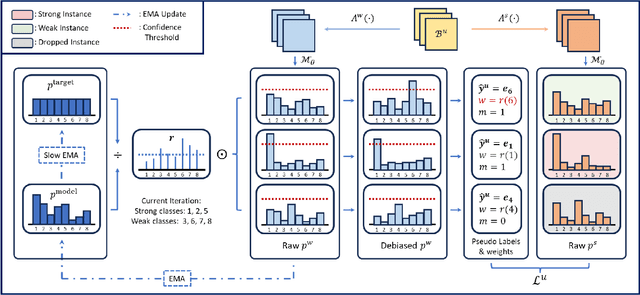
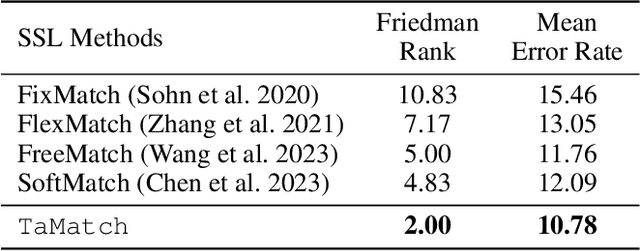
Semi-supervised learning (SSL) commonly exhibits confirmation bias, where models disproportionately favor certain classes, leading to errors in predicted pseudo labels that accumulate under a self-training paradigm. Unlike supervised settings, which benefit from a rich, static data distribution, SSL inherently lacks mechanisms to correct this self-reinforced bias, necessitating debiased interventions at each training step. Although the generation of debiased pseudo labels has been extensively studied, their effective utilization remains underexplored. Our analysis indicates that data from biased classes should have a reduced influence on parameter updates, while more attention should be given to underrepresented classes. To address these challenges, we introduce TaMatch, a unified framework for debiased training in SSL. TaMatch employs a scaling ratio derived from both a prior target distribution and the model's learning status to estimate and correct bias at each training step. This ratio adjusts the raw predictions on unlabeled data to produce debiased pseudo labels. In the utilization phase, these labels are differently weighted according to their predicted class, enhancing training equity and minimizing class bias. Additionally, TaMatch dynamically adjust the target distribution in response to the model's learning progress, facilitating robust handling of practical scenarios where the prior distribution is unknown. Empirical evaluations show that TaMatch significantly outperforms existing state-of-the-art methods across a range of challenging image classification tasks, highlighting the critical importance of both the debiased generation and utilization of pseudo labels in SSL.