 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards the Creation of a Large Corpus of Synthetically-Identified Clinical Notes
Paper and Code
Mar 07, 2018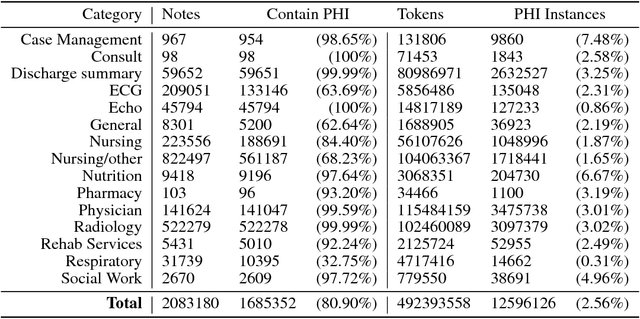
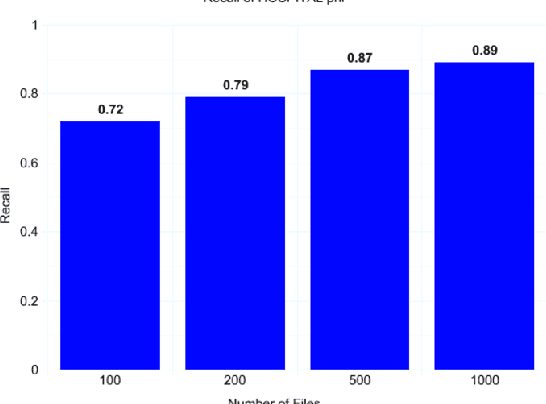

Clinical notes often describe the most important aspects of a patient's physiology and are therefore critical to medical research. However, these notes are typically inaccessible to researchers without prior removal of sensitive protected health information (PHI), a natural language processing (NLP) task referred to as deidentification. Tools to automatically de-identify clinical notes are needed but are difficult to create without access to those very same notes containing PHI. This work presents a first step toward creating a large synthetically-identified corpus of clinical notes and corresponding PHI annotations in order to facilitate the development de-identification tools. Further, one such tool is evaluated against this corpus in order to understand the advantages and shortcomings of this approach.