 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards stability and optimality in stochastic gradient descent
Paper and Code
Jun 07, 2016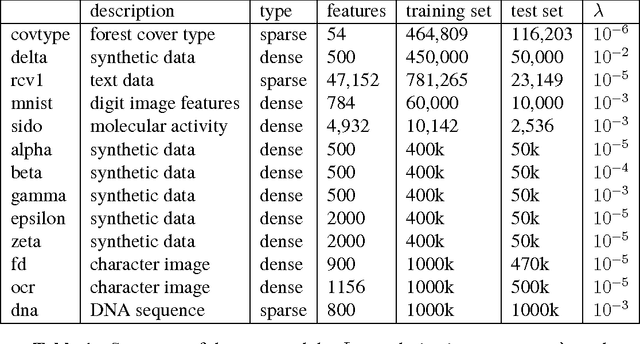
Iterative procedures for parameter estimation based on stochastic gradient descent allow the estimation to scale to massive data sets. However, in both theory and practice, they suffer from numerical instability. Moreover, they are statistically inefficient as estimators of the true parameter value. To address these two issues, we propose a new iterative procedure termed averaged implicit SGD (AI-SGD). For statistical efficiency, AI-SGD employs averaging of the iterates, which achieves the optimal Cram\'{e}r-Rao bound under strong convexity, i.e., it is an optimal unbiased estimator of the true parameter value. For numerical stability, AI-SGD employs an implicit update at each iteration, which is related to proximal operators in optimization. In practice, AI-SGD achieves competitive performance with other state-of-the-art procedures. Furthermore, it is more stable than averaging procedures that do not employ proximal updates, and is simple to implement as it requires fewer tunable hyperparameters than procedures that do employ proximal updates.