 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Learning with Different Label Noise Distributions
Paper and Code



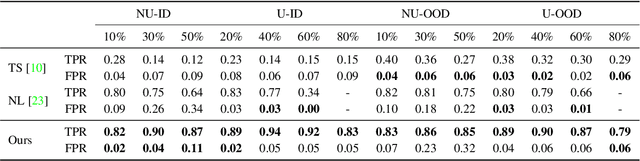
Noisy labels are an unavoidable consequence of automatic image labeling processes to reduce human supervision. Training in these conditions leads Convolutional Neural Networks to memorize label noise and degrade performance. Noisy labels are therefore dispensable, while image content can be exploited in a semi-supervised learning (SSL) setup. Handling label noise then becomes a label noise detection task. Noisy/clean samples are usually identified using the \textit{small loss trick}, which is based on the observation that clean samples represent easier patterns and, therefore, exhibit a lower loss. However, we show that different noise distributions make the application of this trick less straightforward. We propose to continuously relabel all images to reveal a loss that facilitates the use of the small loss trick with different noise distributions. SSL is then applied twice, once to improve the clean-noisy detection and again for training the final model. We design an experimental setup for better understanding the consequences of differing label noise distributions and find that non-uniform out-of-distribution noise better resembles real-world noise. We show that SSL outperforms other alternatives when using oracles and demonstrate substantial improvements across five datasets of our label noise Distribution Robust Pseudo-Labeling (DRPL). We further study the effects of label noise memorization via linear probes and find that in most cases intermediate features are not affected by label noise corruption. Code and details to reproduce our framework will be made available.