 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Open-Set Text Recognition via Label-to-Prototype Learning
Paper and Code
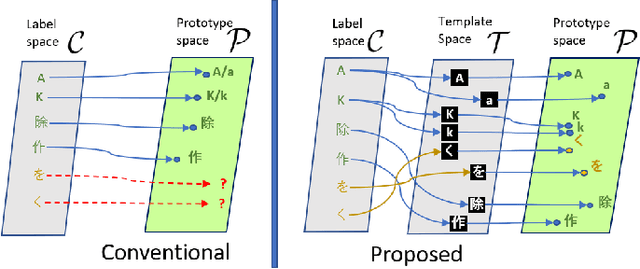

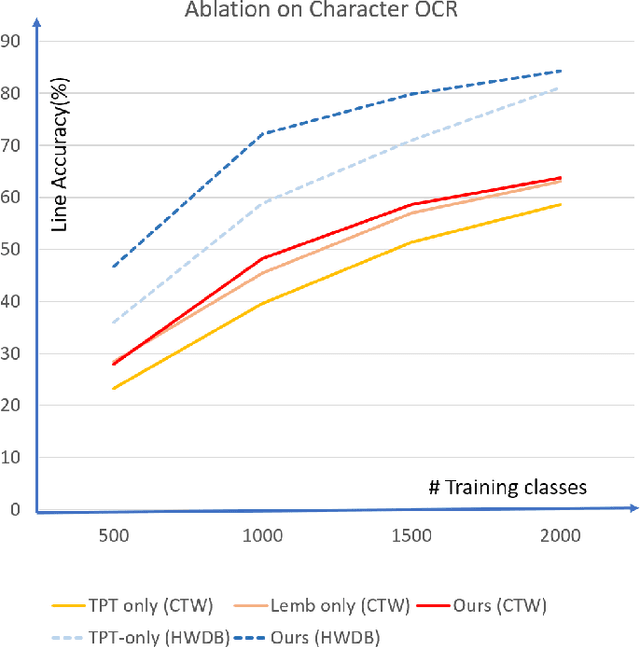
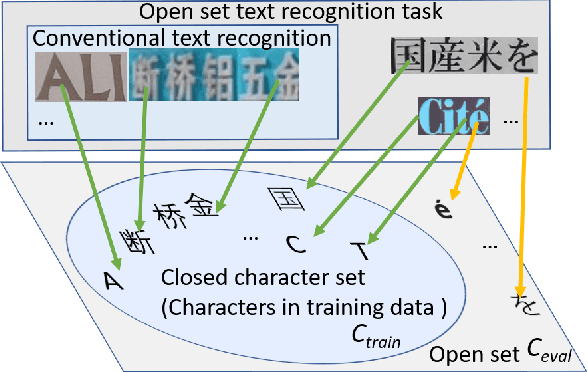
Scene text recognition is a popular topic and extensively used in the industry. Although many methods have achieved satisfactory performance for the close-set text recognition challenges, these methods lose feasibility in open-set scenarios, where collecting data or retraining models for novel characters is too expensive. E.g., annotating samples for foreign languages can be expensive, whereas retraining the model each time a "novel" character is discovered from historical documents also costs time and resources. In this paper, we introduce and formulate a new task, i.e., the open-set text recognition task, which demands the capability to spot and cognize novel characters without retraining. Here, we propose a label-to-prototype learning framework that fulfills the new requirements in the proposed task. Specifically, novel characters are mapped to their corresponding prototypes with a Label-to-Prototype Learning module. The module is trained on seen labels and holds generalization capability for generating class centers for novel characters without retraining. The framework also implements rejection capability over out-of-set characters, which allows spotting unknown characters during the evaluation process. Extensive experiments show that our method achieves promising performance on a variety of zero-shot, close-set, and open-set text recognition datasets.