 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Online End-to-end Transformer Automatic Speech Recognition
Paper and Code
Oct 25, 2019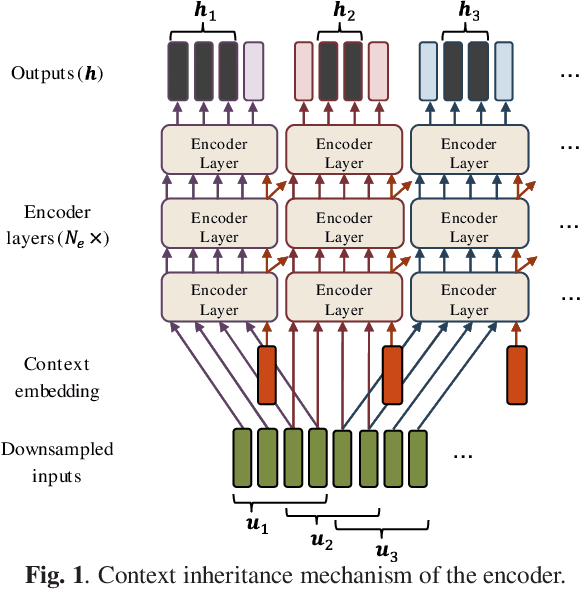
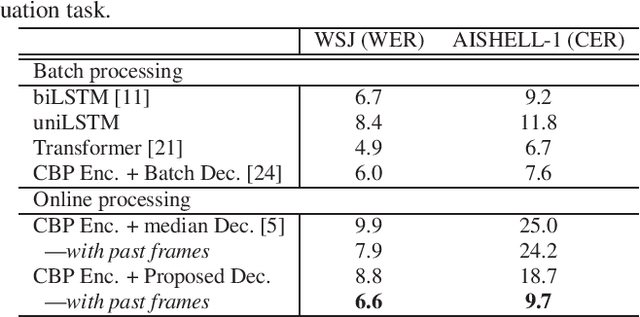
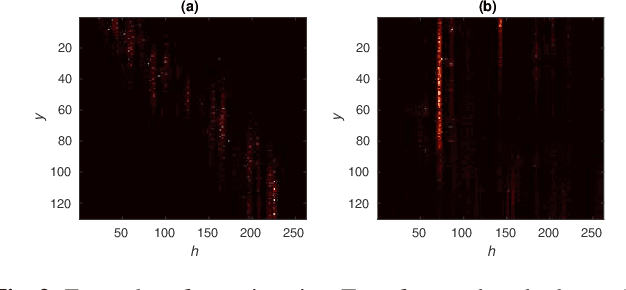
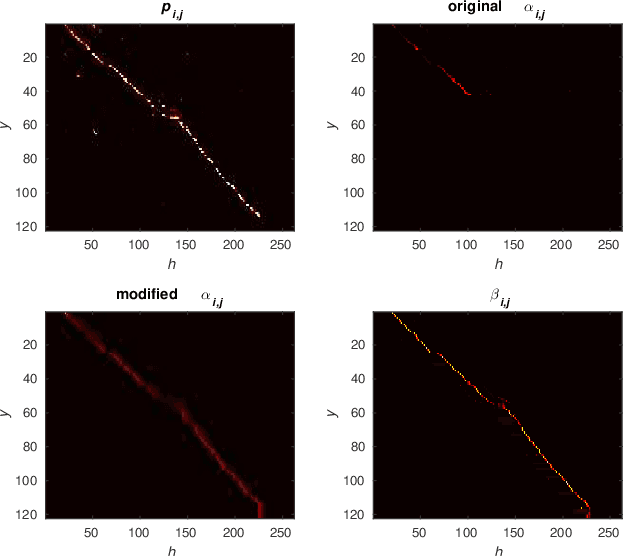
The Transformer self-attention network has recently shown promising performance as an alternative to recurrent neural networks in end-to-end (E2E) automatic speech recognition (ASR) systems. However, Transformer has a drawback in that the entire input sequence is required to compute self-attention. We have proposed a block processing method for the Transformer encoder by introducing a context-aware inheritance mechanism. An additional context embedding vector handed over from the previously processed block helps to encode not only local acoustic information but also global linguistic, channel, and speaker attributes. In this paper, we extend it towards an entire online E2E ASR system by introducing an online decoding process inspired by monotonic chunkwise attention (MoChA) into the Transformer decoder. Our novel MoChA training and inference algorithms exploit the unique properties of Transformer, whose attentions are not always monotonic or peaky, and have multiple heads and residual connections of the decoder layers. Evaluations of the Wall Street Journal (WSJ) and AISHELL-1 show that our proposed online Transformer decoder outperforms conventional chunkwise approaches.