 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Noise-adaptive, Problem-adaptive Stochastic Gradient Descent
Paper and Code
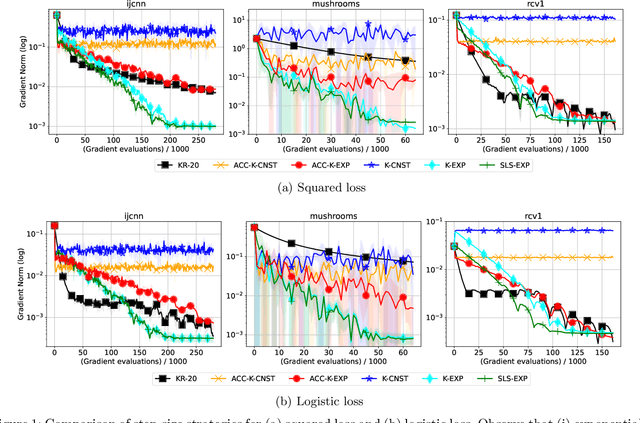
We design step-size schemes that make stochastic gradient descent (SGD) adaptive to (i) the noise $\sigma^2$ in the stochastic gradients and (ii) problem-dependent constants. When minimizing smooth, strongly-convex functions with condition number $\kappa$, we first prove that $T$ iterations of SGD with Nesterov acceleration and exponentially decreasing step-sizes can achieve a near-optimal $\tilde{O}(\exp(-T/\sqrt{\kappa}) + \sigma^2/T)$ convergence rate. Under a relaxed assumption on the noise, with the same step-size scheme and knowledge of the smoothness, we prove that SGD can achieve an $\tilde{O}(\exp(-T/\kappa) + \sigma^2/T)$ rate. In order to be adaptive to the smoothness, we use a stochastic line-search (SLS) and show (via upper and lower-bounds) that SGD converges at the desired rate, but only to a neighbourhood of the solution. Next, we use SGD with an offline estimate of the smoothness and prove convergence to the minimizer. However, its convergence is slowed down proportional to the estimation error and we prove a lower-bound justifying this slowdown. Compared to other step-size schemes, we empirically demonstrate the effectiveness of exponential step-sizes coupled with a novel variant of SLS.