 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Multimodal Understanding of Passenger-Vehicle Interactions in Autonomous Vehicles: Intent/Slot Recognition Utilizing Audio-Visual Data
Paper and Code



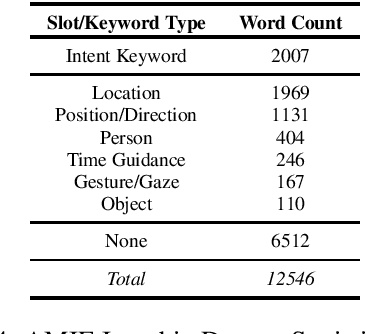
Understanding passenger intents from spoken interactions and car's vision (both inside and outside the vehicle) are important building blocks towards developing contextual dialog systems for natural interactions in autonomous vehicles (AV). In this study, we continued exploring AMIE (Automated-vehicle Multimodal In-cabin Experience), the in-cabin agent responsible for handling certain multimodal passenger-vehicle interactions. When the passengers give instructions to AMIE, the agent should parse such commands properly considering available three modalities (language/text, audio, video) and trigger the appropriate functionality of the AV system. We had collected a multimodal in-cabin dataset with multi-turn dialogues between the passengers and AMIE using a Wizard-of-Oz scheme via realistic scavenger hunt game. In our previous explorations, we experimented with various RNN-based models to detect utterance-level intents (set destination, change route, go faster, go slower, stop, park, pull over, drop off, open door, and others) along with intent keywords and relevant slots (location, position/direction, object, gesture/gaze, time-guidance, person) associated with the action to be performed in our AV scenarios. In this recent work, we propose to discuss the benefits of multimodal understanding of in-cabin utterances by incorporating verbal/language input (text and speech embeddings) together with the non-verbal/acoustic and visual input from inside and outside the vehicle (i.e., passenger gestures and gaze from in-cabin video stream, referred objects outside of the vehicle from the road view camera stream). Our experimental results outperformed text-only baselines and with multimodality, we achieved improved performances for utterance-level intent detection and slot filling.