 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Language-guided Visual Recognition via Dynamic Convolutions
Paper and Code
Oct 17, 2021
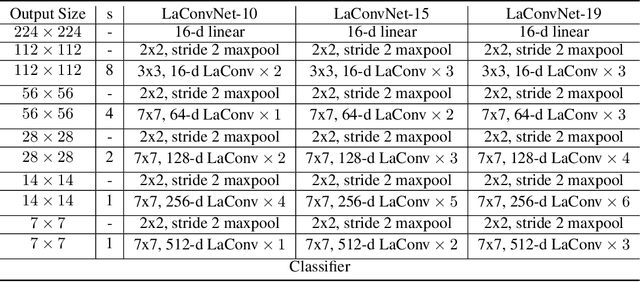

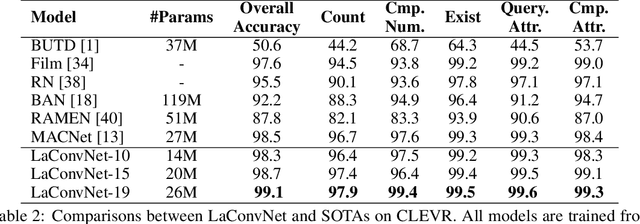
In this paper, we are committed to establishing an unified and end-to-end multi-modal network via exploring the language-guided visual recognition. To approach this target, we first propose a novel multi-modal convolution module called Language-dependent Convolution (LaConv). Its convolution kernels are dynamically generated based on natural language information, which can help extract differentiated visual features for different multi-modal examples. Based on the LaConv module, we further build the first fully language-driven convolution network, termed as LaConvNet, which can unify the visual recognition and multi-modal reasoning in one forward structure. To validate LaConv and LaConvNet, we conduct extensive experiments on four benchmark datasets of two vision-and-language tasks, i.e., visual question answering (VQA) and referring expression comprehension (REC). The experimental results not only shows the performance gains of LaConv compared to the existing multi-modal modules, but also witness the merits of LaConvNet as an unified network, including compact network, high generalization ability and excellent performance, e.g., +4.7% on RefCOCO+.