 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Ground Truth Explainability on Tabular Data
Paper and Code
Jul 20, 2020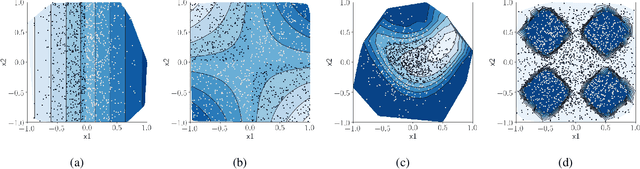
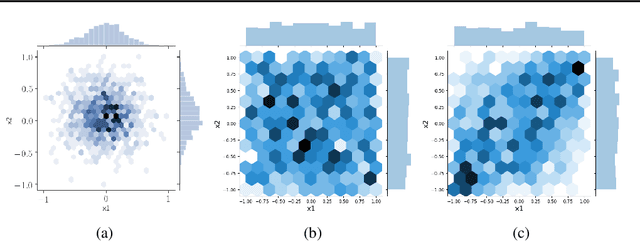
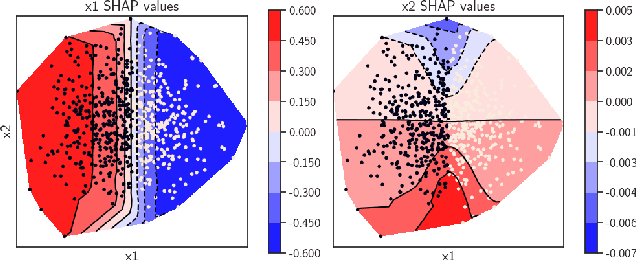
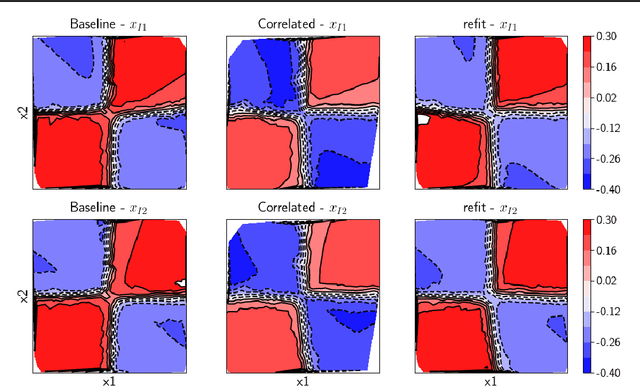
In data science, there is a long history of using synthetic data for method development, feature selection and feature engineering. Our current interest in synthetic data comes from recent work in explainability. Today's datasets are typically larger and more complex - requiring less interpretable models. In the setting of \textit{post hoc} explainability, there is no ground truth for explanations. Inspired by recent work in explaining image classifiers that does provide ground truth, we propose a similar solution for tabular data. Using copulas, a concise specification of the desired statistical properties of a dataset, users can build intuition around explainability using controlled data sets and experimentation. The current capabilities are demonstrated on three use cases: one dimensional logistic regression, impact of correlation from informative features, impact of correlation from redundant variables.