 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Federated Long-Tailed Learning
Paper and Code
Jun 30, 2022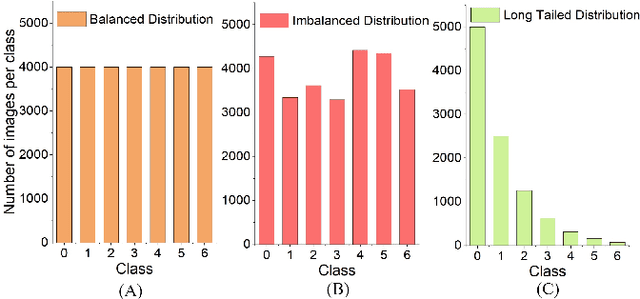
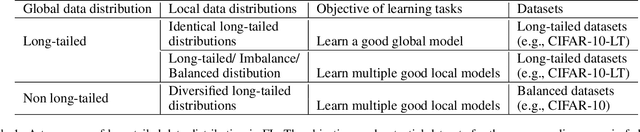
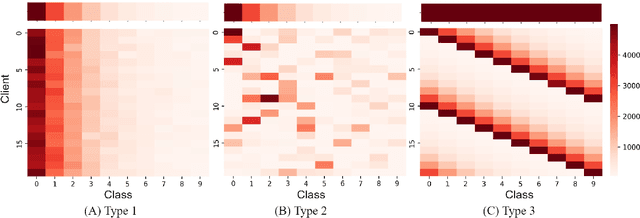
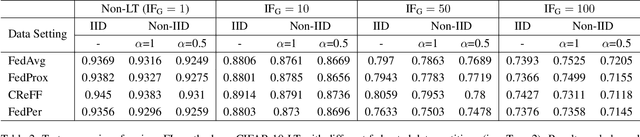
Data privacy and class imbalance are the norm rather than the exception in many machine learning tasks. Recent attempts have been launched to, on one side, address the problem of learning from pervasive private data, and on the other side, learn from long-tailed data. However, both assumptions might hold in practical applications, while an effective method to simultaneously alleviate both issues is yet under development. In this paper, we focus on learning with long-tailed (LT) data distributions under the context of the popular privacy-preserved federated learning (FL) framework. We characterize three scenarios with different local or global long-tailed data distributions in the FL framework, and highlight the corresponding challenges. The preliminary results under different scenarios reveal that substantial future work are of high necessity to better resolve the characterized federated long-tailed learning tasks.