 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Better Generalization: BP-SVRG in Training Deep Neural Networks
Paper and Code



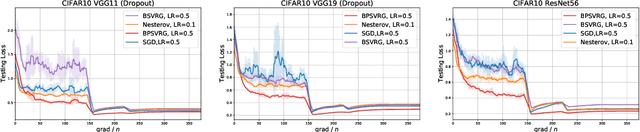
Stochastic variance-reduced gradient (SVRG) is a classical optimization method. Although it is theoretically proved to have better convergence performance than stochastic gradient descent (SGD), the generalization performance of SVRG remains open. In this paper we investigate the effects of some training techniques, mini-batching and learning rate decay, on the generalization performance of SVRG, and verify the generalization performance of Batch-SVRG (B-SVRG). In terms of the relationship between optimization and generalization, we believe that the average norm of gradients on each training sample as well as the norm of average gradient indicate how flat the landscape is and how well the model generalizes. Based on empirical observations of such metrics, we perform a sign switch on B-SVRG and derive a practical algorithm, BatchPlus-SVRG (BP-SVRG), which is numerically shown to enjoy better generalization performance than B-SVRG, even SGD in some scenarios of deep neural networks.