 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards an Intrinsic Definition of Robustness for a Classifier
Paper and Code

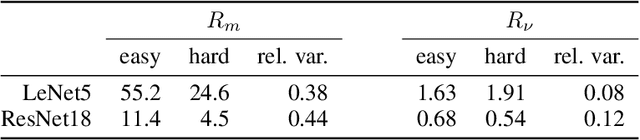

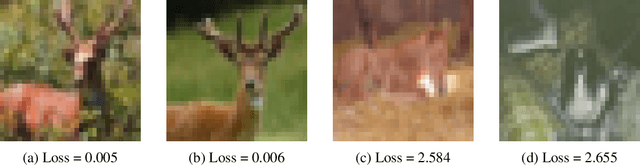
The robustness of classifiers has become a question of paramount importance in the past few years. Indeed, it has been shown that state-of-the-art deep learning architectures can easily be fooled with imperceptible changes to their inputs. Therefore, finding good measures of robustness of a trained classifier is a key issue in the field. In this paper, we point out that averaging the radius of robustness of samples in a validation set is a statistically weak measure. We propose instead to weight the importance of samples depending on their difficulty. We motivate the proposed score by a theoretical case study using logistic regression, where we show that the proposed score is independent of the choice of the samples it is evaluated upon. We also empirically demonstrate the ability of the proposed score to measure robustness of classifiers with little dependence on the choice of samples in more complex settings, including deep convolutional neural networks and real datasets.