 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Guideline for Evaluation Metrics in Medical Image Segmentation
Paper and Code
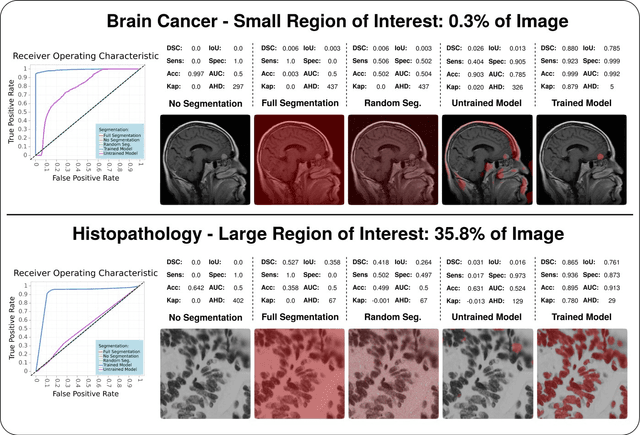
In the last decade, research on artificial intelligence has seen rapid growth with deep learning models, especially in the field of medical image segmentation. Various studies demonstrated that these models have powerful prediction capabilities and achieved similar results as clinicians. However, recent studies revealed that the evaluation in image segmentation studies lacks reliable model performance assessment and showed statistical bias by incorrect metric implementation or usage. Thus, this work provides an overview and interpretation guide on the following metrics for medical image segmentation evaluation in binary as well as multi-class problems: Dice similarity coefficient, Jaccard, Sensitivity, Specificity, Rand index, ROC curves, Cohen's Kappa, and Hausdorff distance. As a summary, we propose a guideline for standardized medical image segmentation evaluation to improve evaluation quality, reproducibility, and comparability in the research field.