 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToPs: Ensemble Learning with Trees of Predictors
Paper and Code
Feb 13, 2018

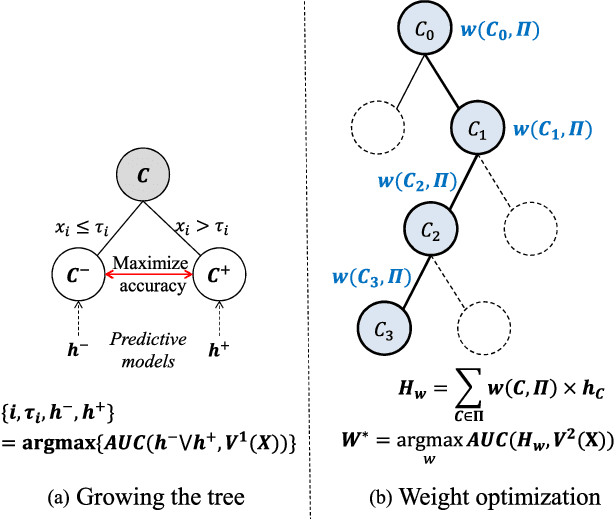
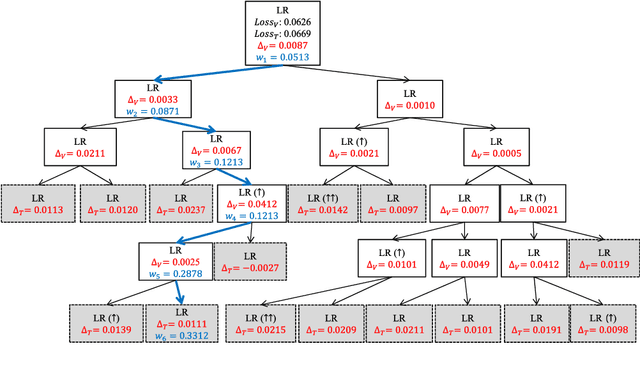
We present a new approach to ensemble learning. Our approach constructs a tree of subsets of the feature space and associates a predictor (predictive model) - determined by training one of a given family of base learners on an endogenously determined training set - to each node of the tree; we call the resulting object a tree of predictors. The (locally) optimal tree of predictors is derived recursively; each step involves jointly optimizing the split of the terminal nodes of the previous tree and the choice of learner and training set (hence predictor) for each set in the split. The feature vector of a new instance determines a unique path through the optimal tree of predictors; the final prediction aggregates the predictions of the predictors along this path. We derive loss bounds for the final predictor in terms of the Rademacher complexity of the base learners. We report the results of a number of experiments on a variety of datasets, showing that our approach provides statistically significant improvements over state-of-the-art machine learning algorithms, including various ensemble learning methods. Our approach works because it allows us to endogenously create more complex learners - when needed - and endogenously match both the learner and the training set to the characteristics of the dataset while still avoiding over-fitting.