 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTop-K Training of GANs: Improving Generators by Making Critics Less Critical
Paper and Code
Feb 14, 2020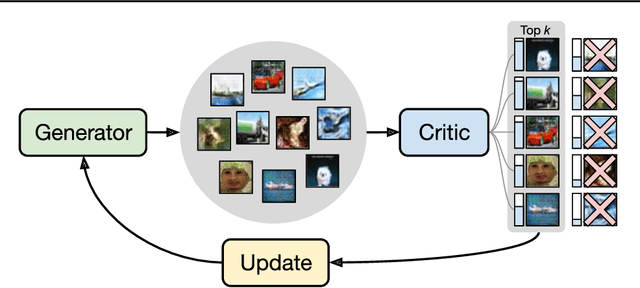

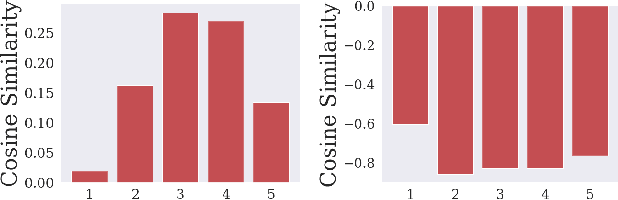
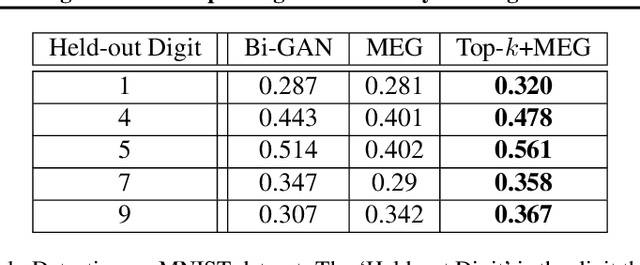
We introduce a simple (one line of code) modification to the Generative Adversarial Network (GAN) training algorithm that materially improves results with no increase in computational cost: When updating the generator parameters, we simply zero out the gradient contributions from the elements of the batch that the critic scores as `least realistic'. Through experiments on many different GAN variants, we show that this `top-k update' procedure is a generally applicable improvement. In order to understand the nature of the improvement, we conduct extensive analysis on a simple mixture-of-Gaussians dataset and discover several interesting phenomena. Among these is that, when gradient updates are computed using the worst-scoring batch elements, samples can actually be pushed further away from the their nearest mode.