 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenMix: Rethinking Image Mixing for Data Augmentation in Vision Transformers
Paper and Code

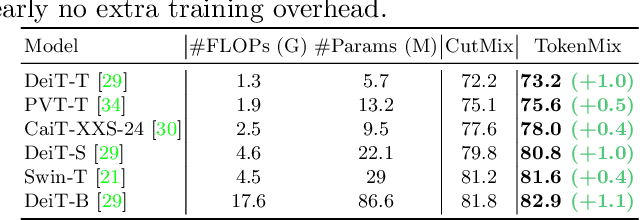
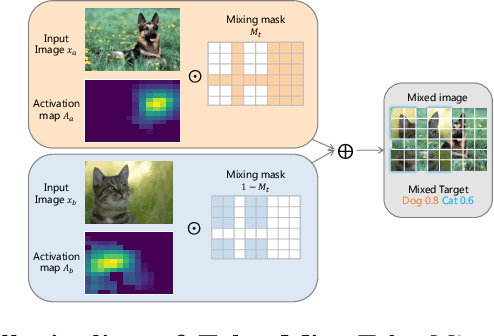

CutMix is a popular augmentation technique commonly used for training modern convolutional and transformer vision networks. It was originally designed to encourage Convolution Neural Networks (CNNs) to focus more on an image's global context instead of local information, which greatly improves the performance of CNNs. However, we found it to have limited benefits for transformer-based architectures that naturally have a global receptive field. In this paper, we propose a novel data augmentation technique TokenMix to improve the performance of vision transformers. TokenMix mixes two images at token level via partitioning the mixing region into multiple separated parts. Besides, we show that the mixed learning target in CutMix, a linear combination of a pair of the ground truth labels, might be inaccurate and sometimes counter-intuitive. To obtain a more suitable target, we propose to assign the target score according to the content-based neural activation maps of the two images from a pre-trained teacher model, which does not need to have high performance. With plenty of experiments on various vision transformer architectures, we show that our proposed TokenMix helps vision transformers focus on the foreground area to infer the classes and enhances their robustness to occlusion, with consistent performance gains. Notably, we improve DeiT-T/S/B with +1% ImageNet top-1 accuracy. Besides, TokenMix enjoys longer training, which achieves 81.2% top-1 accuracy on ImageNet with DeiT-S trained for 400 epochs. Code is available at https://github.com/Sense-X/TokenMix.