 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Learn or Not to Learn: Visual Localization from Essential Matrices
Paper and Code
Aug 04, 2019


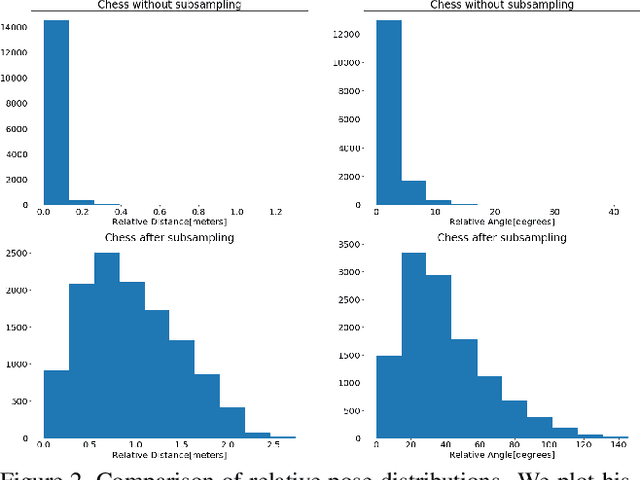
Visual localization is the problem of estimating a camera within a scene and a key component in computer vision applications such as self-driving cars and Mixed Reality. State-of-the-art approaches for accurate visual localization use scene-specific representations, resulting in the overhead of constructing these models when applying the techniques to new scenes. Recently, deep learning-based approaches based on relative pose estimation have been proposed, carrying the promise of easily adapting to new scenes. However, it has been shown such approaches are currently significantly less accurate than state-of-the-art approaches. In this paper, we are interested in analyzing this behavior. To this end, we propose a novel framework for visual localization from relative poses. Using a classical feature-based approach within this framework, we show state-of-the-art performance. Replacing the classical approach with learned alternatives at various levels, we then identify the reasons for why deep learned approaches do not perform well. Based on our analysis, we make recommendations for future work.