Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime manipulation technique for speeding up reinforcement learning in simulations
Paper and Code
Mar 28, 2009
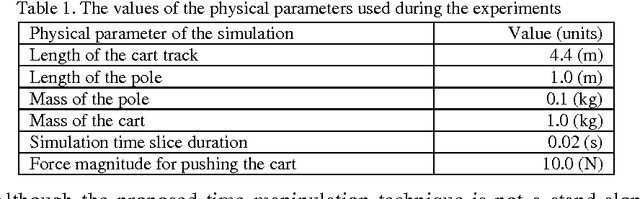
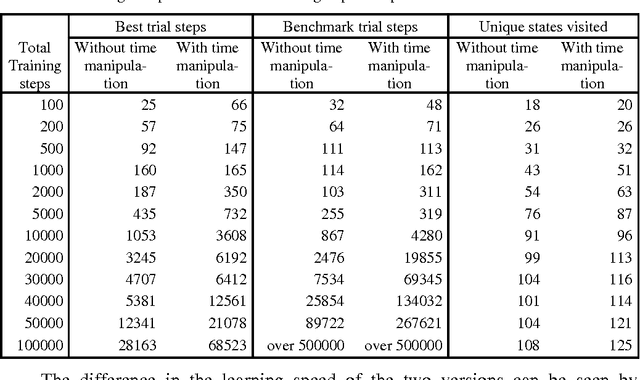
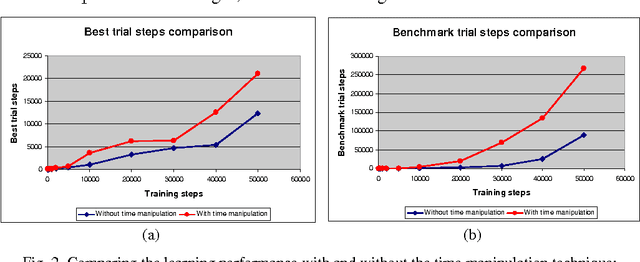
A technique for speeding up reinforcement learning algorithms by using time manipulation is proposed. It is applicable to failure-avoidance control problems running in a computer simulation. Turning the time of the simulation backwards on failure events is shown to speed up the learning by 260% and improve the state space exploration by 12% on the cart-pole balancing task, compared to the conventional Q-learning and Actor-Critic algorithms.
* International Journal of Cybernetics and Information Technologies,
vol. 8, no. 1, pp. 12-24, 2008 * 12 pages
View paper on