 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTighter risk certificates for neural networks
Paper and Code
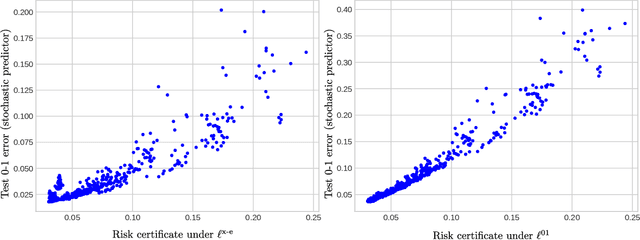

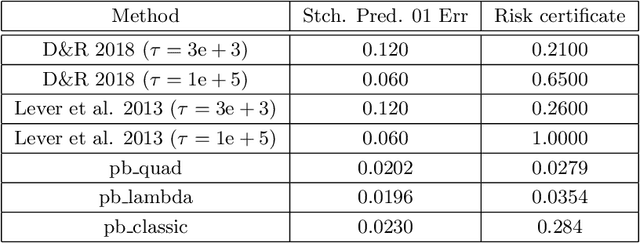

This paper presents an empirical study regarding training probabilistic neural networks using training objectives derived from PAC-Bayes bounds. In the context of probabilistic neural networks, the output of training is a probability distribution over network weights. We present two training objectives, used here for the first time in connection with training neural networks. These two training objectives are derived from tight PAC-Bayes bounds. We also re-implement a previously used training objective based on a classical PAC-Bayes bound, to compare the properties of the predictors learned using the different training objectives. We compute risk certificates that are valid on any unseen examples for the learnt predictors. We further experiment with different types of priors on the weights (both data-free and data-dependent priors) and neural network architectures. Our experiments on MNIST and CIFAR-10 show that our training methods produce competitive test set errors and non-vacuous risk bounds with much tighter values than previous results in the literature, showing promise not only to guide the learning algorithm through bounding the risk but also for model selection. These observations suggest that the methods studied here might be good candidates for self-certified learning, in the sense of certifying the risk on any unseen data without the need for data-splitting protocols.