 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThompson Sampling Itself is Differentially Private
Paper and Code
Jul 20, 2024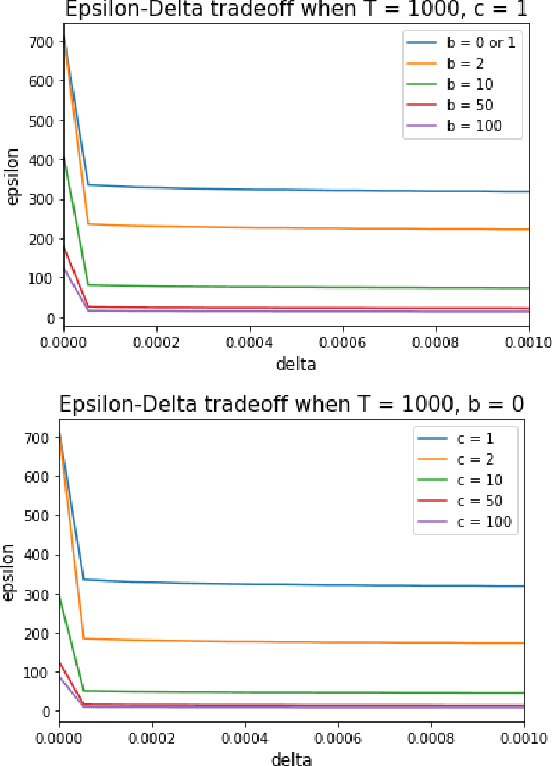
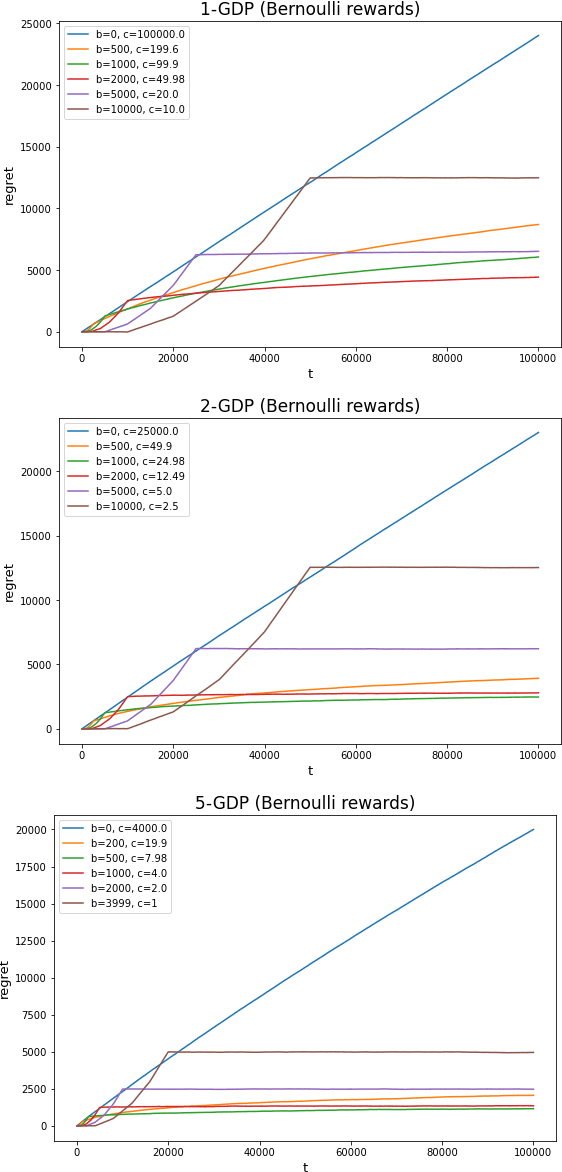
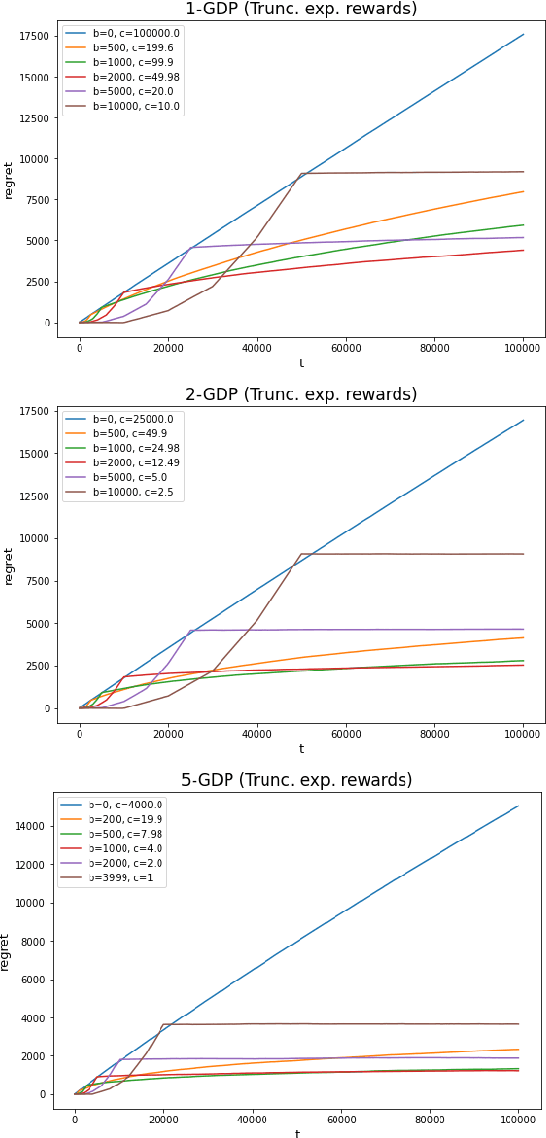
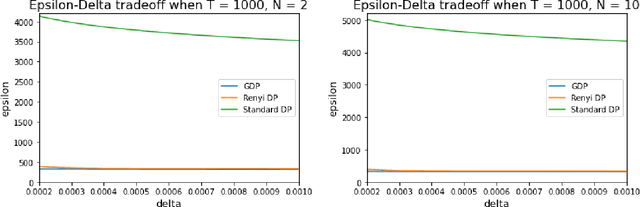
In this work we first show that the classical Thompson sampling algorithm for multi-arm bandits is differentially private as-is, without any modification. We provide per-round privacy guarantees as a function of problem parameters and show composition over $T$ rounds; since the algorithm is unchanged, existing $O(\sqrt{NT\log N})$ regret bounds still hold and there is no loss in performance due to privacy. We then show that simple modifications -- such as pre-pulling all arms a fixed number of times, increasing the sampling variance -- can provide tighter privacy guarantees. We again provide privacy guarantees that now depend on the new parameters introduced in the modification, which allows the analyst to tune the privacy guarantee as desired. We also provide a novel regret analysis for this new algorithm, and show how the new parameters also impact expected regret. Finally, we empirically validate and illustrate our theoretical findings in two parameter regimes and demonstrate that tuning the new parameters substantially improve the privacy-regret tradeoff.