 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe YLI-MED Corpus: Characteristics, Procedures, and Plans
Paper and Code
Mar 13, 2015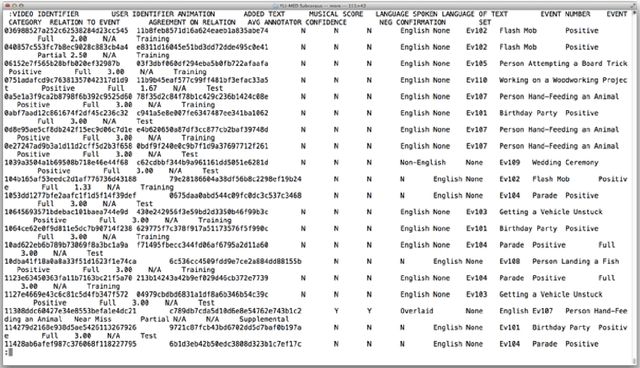


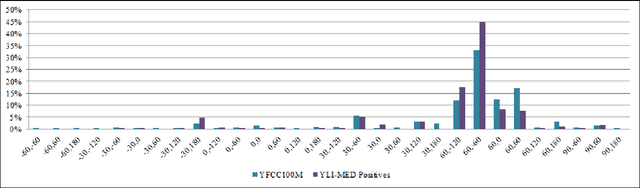
The YLI Multimedia Event Detection corpus is a public-domain index of videos with annotations and computed features, specialized for research in multimedia event detection (MED), i.e., automatically identifying what's happening in a video by analyzing the audio and visual content. The videos indexed in the YLI-MED corpus are a subset of the larger YLI feature corpus, which is being developed by the International Computer Science Institute and Lawrence Livermore National Laboratory based on the Yahoo Flickr Creative Commons 100 Million (YFCC100M) dataset. The videos in YLI-MED are categorized as depicting one of ten target events, or no target event, and are annotated for additional attributes like language spoken and whether the video has a musical score. The annotations also include degree of annotator agreement and average annotator confidence scores for the event categorization of each video. Version 1.0 of YLI-MED includes 1823 "positive" videos that depict the target events and 48,138 "negative" videos, as well as 177 supplementary videos that are similar to event videos but are not positive examples. Our goal in producing YLI-MED is to be as open about our data and procedures as possible. This report describes the procedures used to collect the corpus; gives detailed descriptive statistics about the corpus makeup (and how video attributes affected annotators' judgments); discusses possible biases in the corpus introduced by our procedural choices and compares it with the most similar existing dataset, TRECVID MED's HAVIC corpus; and gives an overview of our future plans for expanding the annotation effort.