 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Trimmed Lasso: Sparse Recovery Guarantees and Practical Optimization by the Generalized Soft-Min Penalty
Paper and Code


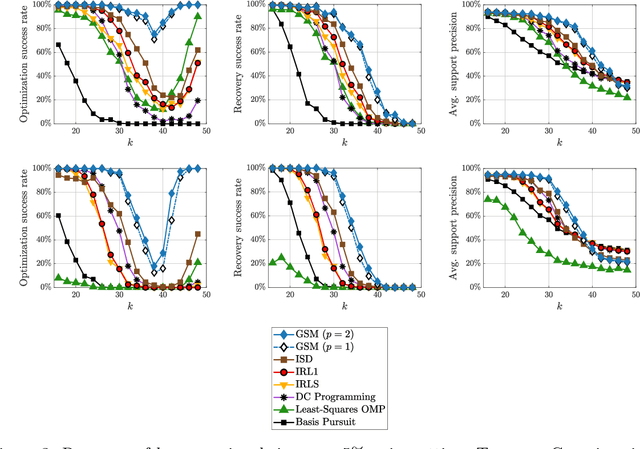
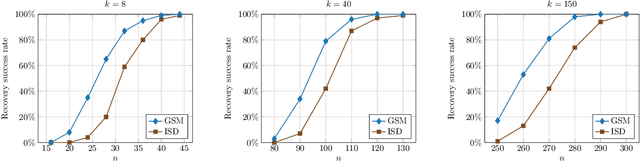
We present a new approach to solve the sparse approximation or best subset selection problem, namely find a $k$-sparse vector ${\bf x}\in\mathbb{R}^d$ that minimizes the $\ell_2$ residual $\lVert A{\bf x}-{\bf y} \rVert_2$. We consider a regularized approach, whereby this residual is penalized by the non-convex $\textit{trimmed lasso}$, defined as the $\ell_1$-norm of ${\bf x}$ excluding its $k$ largest-magnitude entries. We prove that the trimmed lasso has several appealing theoretical properties, and in particular derive sparse recovery guarantees assuming successful optimization of the penalized objective. Next, we show empirically that directly optimizing this objective can be quite challenging. Instead, we propose a surrogate for the trimmed lasso, called the $\textit{generalized soft-min}$. This penalty smoothly interpolates between the classical lasso and the trimmed lasso, while taking into account all possible $k$-sparse patterns. The generalized soft-min penalty involves summation over $\binom{d}{k}$ terms, yet we derive a polynomial-time algorithm to compute it. This, in turn, yields a practical method for the original sparse approximation problem. Via simulations, we demonstrate its competitive performance compared to current state of the art.