 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Theory is Predictive, but is it Complete? An Application to Human Perception of Randomness
Paper and Code
Jun 21, 2017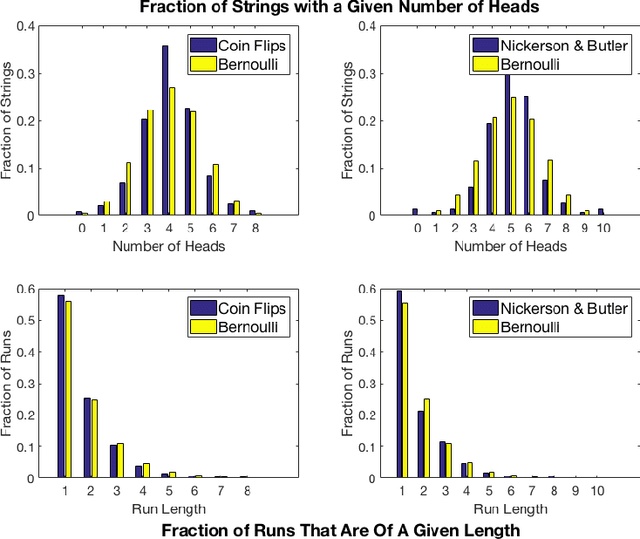
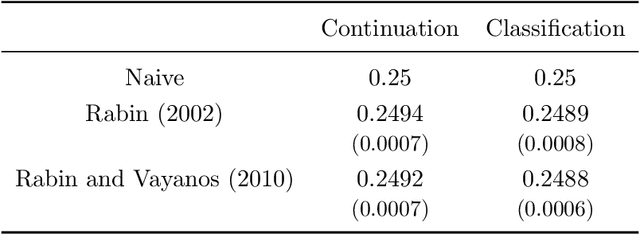


When we test a theory using data, it is common to focus on correctness: do the predictions of the theory match what we see in the data? But we also care about completeness: how much of the predictable variation in the data is captured by the theory? This question is difficult to answer, because in general we do not know how much "predictable variation" there is in the problem. In this paper, we consider approaches motivated by machine learning algorithms as a means of constructing a benchmark for the best attainable level of prediction. We illustrate our methods on the task of predicting human-generated random sequences. Relative to an atheoretical machine learning algorithm benchmark, we find that existing behavioral models explain roughly 15 percent of the predictable variation in this problem. This fraction is robust across several variations on the problem. We also consider a version of this approach for analyzing field data from domains in which human perception and generation of randomness has been used as a conceptual framework; these include sequential decision-making and repeated zero-sum games. In these domains, our framework for testing the completeness of theories provides a way of assessing their effectiveness over different contexts; we find that despite some differences, the existing theories are fairly stable across our field domains in their performance relative to the benchmark. Overall, our results indicate that (i) there is a significant amount of structure in this problem that existing models have yet to capture and (ii) there are rich domains in which machine learning may provide a viable approach to testing completeness.