 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Stochastic Replica Approach to Machine Learning: Stability and Parameter Optimization
Paper and Code
Oct 13, 2017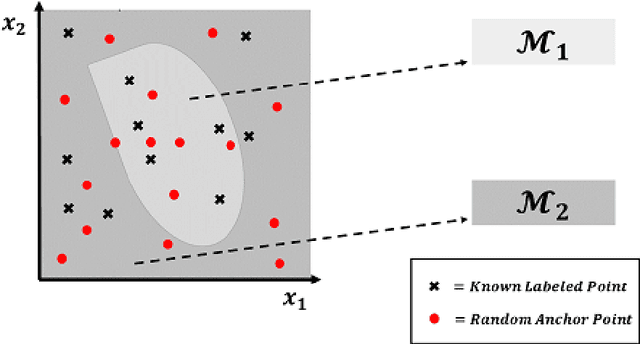


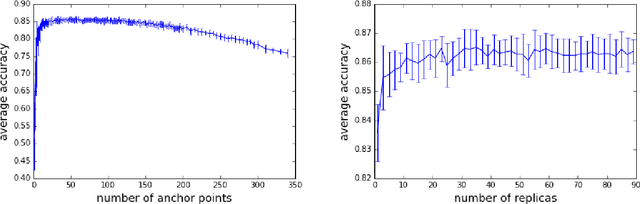
We introduce a statistical physics inspired supervised machine learning algorithm for classification and regression problems. The method is based on the invariances or stability of predicted results when known data is represented as expansions in terms of various stochastic functions. The algorithm predicts the classification/regression values of new data by combining (via voting) the outputs of these numerous linear expansions in randomly chosen functions. The few parameters (typically only one parameter is used in all studied examples) that this model has may be automatically optimized. The algorithm has been tested on 10 diverse training data sets of various types and feature space dimensions. It has been shown to consistently exhibit high accuracy and readily allow for optimization of parameters, while simultaneously avoiding pitfalls of existing algorithms such as those associated with class imbalance. We very briefly speculate on whether spatial coordinates in physical theories may be viewed as emergent "features" that enable a robust machine learning type description of data with generic low order smooth functions.