 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe SJTU System for Short-duration Speaker Verification Challenge 2021
Paper and Code
Aug 03, 2022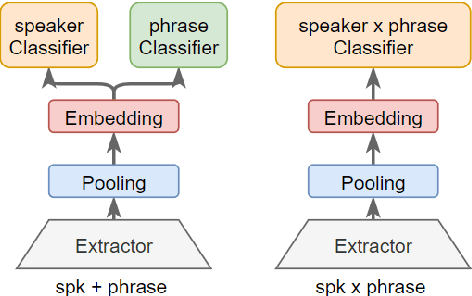
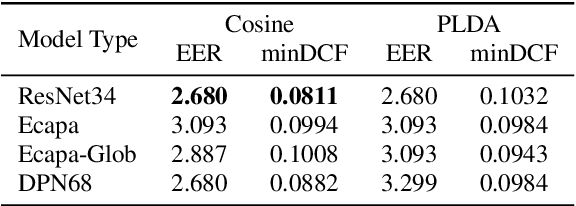
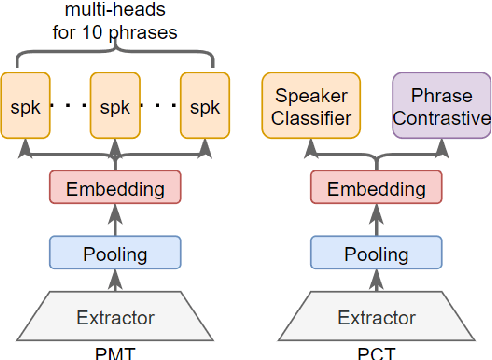
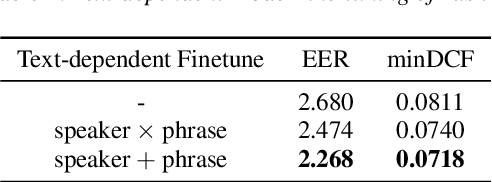
This paper presents the SJTU system for both text-dependent and text-independent tasks in short-duration speaker verification (SdSV) challenge 2021. In this challenge, we explored different strong embedding extractors to extract robust speaker embedding. For text-independent task, language-dependent adaptive snorm is explored to improve the system performance under the cross-lingual verification condition. For text-dependent task, we mainly focus on the in-domain fine-tuning strategies based on the model pre-trained on large-scale out-of-domain data. In order to improve the distinction between different speakers uttering the same phrase, we proposed several novel phrase-aware fine-tuning strategies and phrase-aware neural PLDA. With such strategies, the system performance is further improved. Finally, we fused the scores of different systems, and our fusion systems achieved 0.0473 in Task1 (rank 3) and 0.0581 in Task2 (rank 8) on the primary evaluation metric.