 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Role of Time Delay in Sim2real Transfer of Reinforcement Learning for Cyber-Physical Systems
Paper and Code
Sep 30, 2022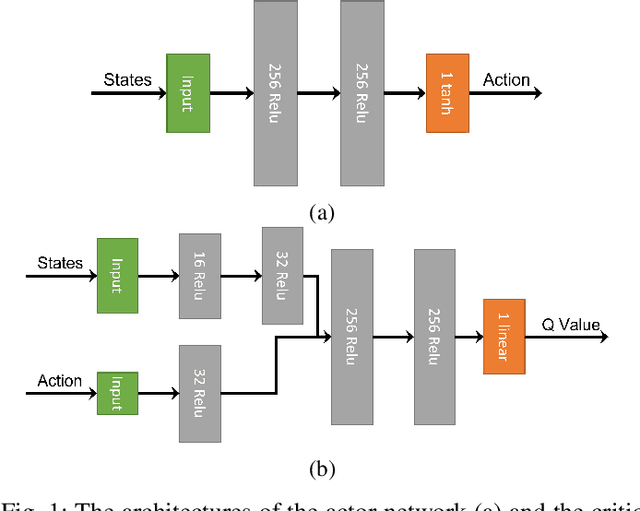

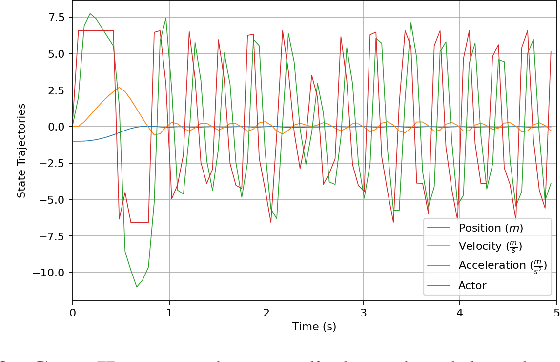

This paper analyzes the simulation to reality gap in reinforcement learning (RL) cyber-physical systems with fractional delays (i.e. delays that are non-integer multiple of the sampling period). The consideration of fractional delay has important implications on the nature of the cyber-physical system considered. Systems with delays are non-Markovian, and the system state vector needs to be extended to make the system Markovian. We show that this is not possible when the delay is in the output, and the problem would always be non-Markovian. Based on this analysis, a sampling scheme is proposed that results in efficient RL training and agents that perform well in realistic multirotor unmanned aerial vehicle simulations. We demonstrate that the resultant agents do not produce excessive oscillations, which is not the case with RL agents that do not consider time delay in the model.