 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Pose Knows: Video Forecasting by Generating Pose Futures
Paper and Code
Apr 28, 2017
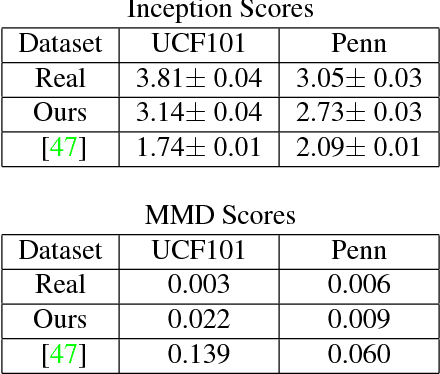


Current approaches in video forecasting attempt to generate videos directly in pixel space using Generative Adversarial Networks (GANs) or Variational Autoencoders (VAEs). However, since these approaches try to model all the structure and scene dynamics at once, in unconstrained settings they often generate uninterpretable results. Our insight is to model the forecasting problem at a higher level of abstraction. Specifically, we exploit human pose detectors as a free source of supervision and break the video forecasting problem into two discrete steps. First we explicitly model the high level structure of active objects in the scene---humans---and use a VAE to model the possible future movements of humans in the pose space. We then use the future poses generated as conditional information to a GAN to predict the future frames of the video in pixel space. By using the structured space of pose as an intermediate representation, we sidestep the problems that GANs have in generating video pixels directly. We show through quantitative and qualitative evaluation that our method outperforms state-of-the-art methods for video prediction.