 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Pitfalls of Simplicity Bias in Neural Networks
Paper and Code
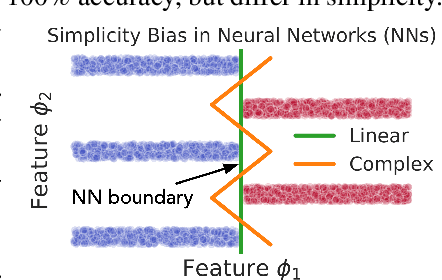

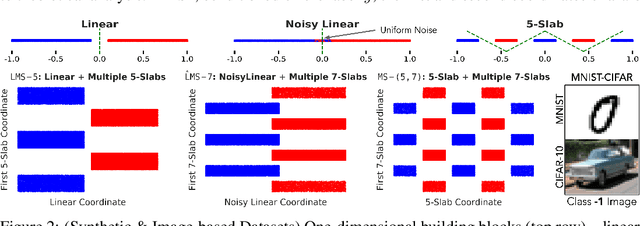
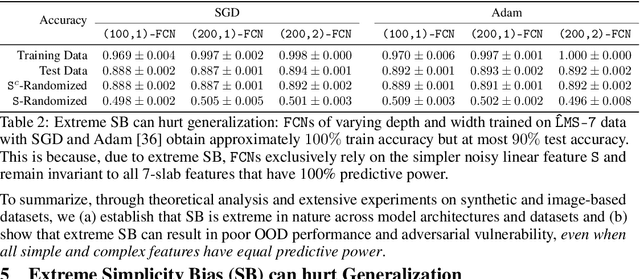
Several works have proposed Simplicity Bias (SB)---the tendency of standard training procedures such as Stochastic Gradient Descent (SGD) to find simple models---to justify why neural networks generalize well [Arpit et al. 2017, Nakkiran et al. 2019, Valle-Perez et al. 2019]. However, the precise notion of simplicity remains vague. Furthermore, previous settings that use SB to justify why neural networks generalize well do not simultaneously capture the brittleness of neural networks---a widely observed phenomenon in practice [Goodfellow et al. 2014, Jo and Bengio 2017]. To this end, we introduce a collection of piecewise-linear and image-based datasets that (a) naturally incorporate a precise notion of simplicity and (b) capture the subtleties of neural networks trained on real datasets. Through theory and experiments on these datasets, we show that SB of SGD and variants is extreme: neural networks rely exclusively on the simplest feature and remain invariant to all predictive complex features. Consequently, the extreme nature of SB explains why seemingly benign distribution shifts and small adversarial perturbations significantly degrade model performance. Moreover, contrary to conventional wisdom, SB can also hurt generalization on the same data distribution, as SB persists even when the simplest feature has less predictive power than the more complex features. We also demonstrate that common approaches for improving generalization and robustness---ensembles and adversarial training---do not mitigate SB and its shortcomings. Given the central role played by SB in generalization and robustness, we hope that the datasets and methods in this paper serve as an effective testbed to evaluate novel algorithmic approaches aimed at avoiding the pitfalls of extreme SB.