 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe LogBarrier adversarial attack: making effective use of decision boundary information
Paper and Code

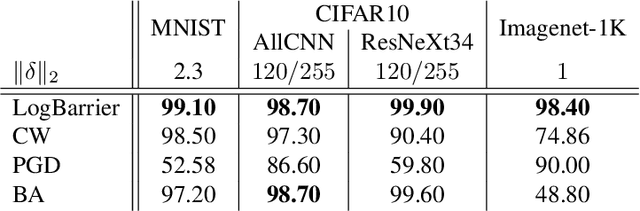

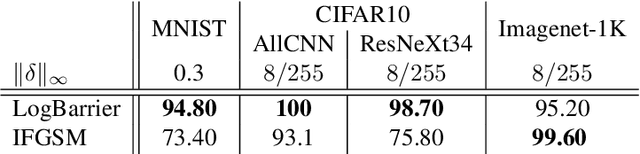
Adversarial attacks for image classification are small perturbations to images that are designed to cause misclassification by a model. Adversarial attacks formally correspond to an optimization problem: find a minimum norm image perturbation, constrained to cause misclassification. A number of effective attacks have been developed. However, to date, no gradient-based attacks have used best practices from the optimization literature to solve this constrained minimization problem. We design a new untargeted attack, based on these best practices, using the established logarithmic barrier method. On average, our attack distance is similar or better than all state-of-the-art attacks on benchmark datasets (MNIST, CIFAR10, ImageNet-1K). In addition, our method performs significantly better on the most challenging images, those which normally require larger perturbations for misclassification. We employ the LogBarrier attack on several adversarially defended models, and show that it adversarially perturbs all images more efficiently than other attacks: the distance needed to perturb all images is significantly smaller with the LogBarrier attack than with other state-of-the-art attacks.