 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Interplay of Variant, Size, and Task Type in Arabic Pre-trained Language Models
Paper and Code
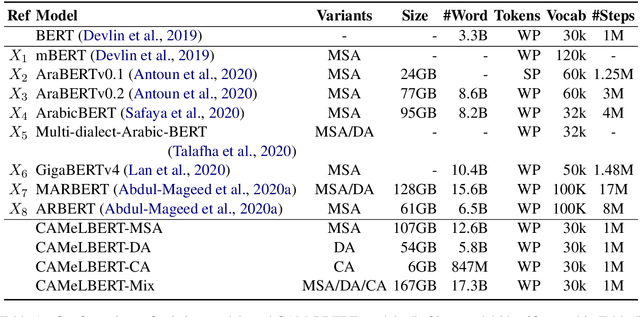
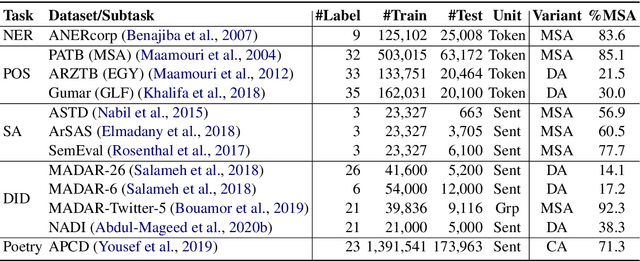
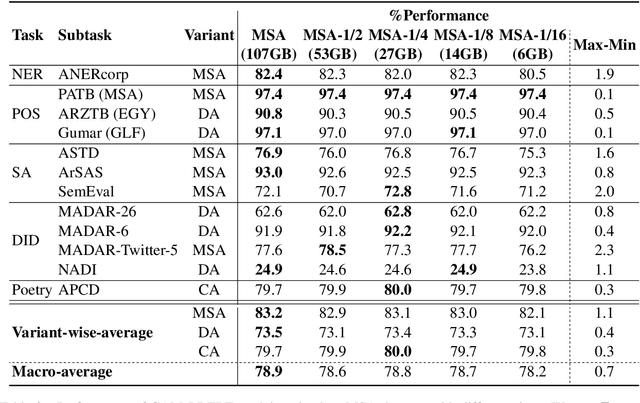
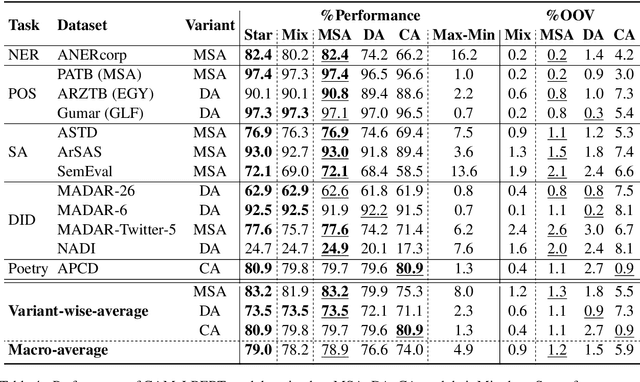
In this paper, we explore the effects of language variants, data sizes, and fine-tuning task types in Arabic pre-trained language models. To do so, we build three pre-trained language models across three variants of Arabic: Modern Standard Arabic (MSA), dialectal Arabic, and classical Arabic, in addition to a fourth language model which is pre-trained on a mix of the three. We also examine the importance of pre-training data size by building additional models that are pre-trained on a scaled-down set of the MSA variant. We compare our different models to each other, as well as to eight publicly available models by fine-tuning them on five NLP tasks spanning 12 datasets. Our results suggest that the variant proximity of pre-training data to fine-tuning data is more important than the pre-training data size. We exploit this insight in defining an optimized system selection model for the studied tasks.