 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Implicit Regularization of Stochastic Gradient Flow for Least Squares
Paper and Code
Mar 17, 2020
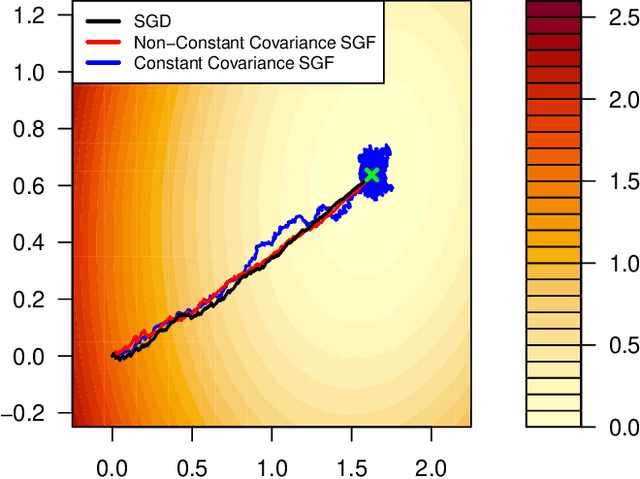
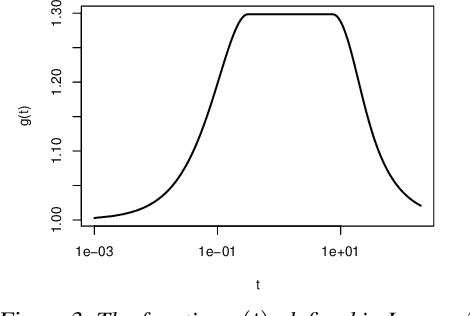
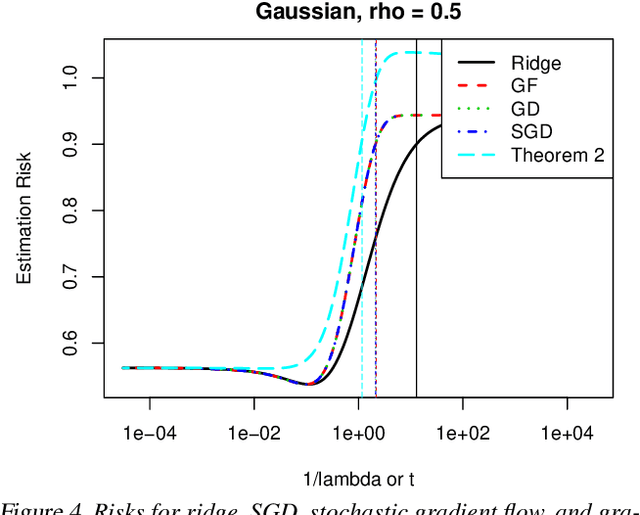
We study the implicit regularization of mini-batch stochastic gradient descent, when applied to the fundamental problem of least squares regression. We leverage a continuous-time stochastic differential equation having the same moments as stochastic gradient descent, which we call stochastic gradient flow. We give a bound on the excess risk of stochastic gradient flow at time $t$, over ridge regression with tuning parameter $\lambda = 1/t$. The bound may be computed from explicit constants (e.g., the mini-batch size, step size, number of iterations), revealing precisely how these quantities drive the excess risk. Numerical examples show the bound can be small, indicating a tight relationship between the two estimators. We give a similar result relating the coefficients of stochastic gradient flow and ridge. These results hold under no conditions on the data matrix $X$, and across the entire optimization path (not just at convergence).