 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Emergence of Objectness: Learning Zero-Shot Segmentation from Videos
Paper and Code
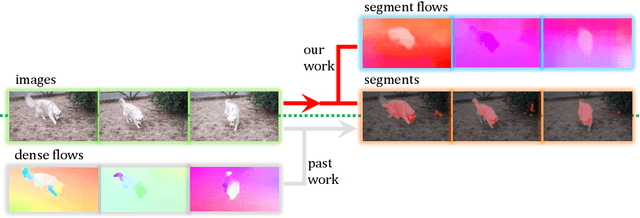

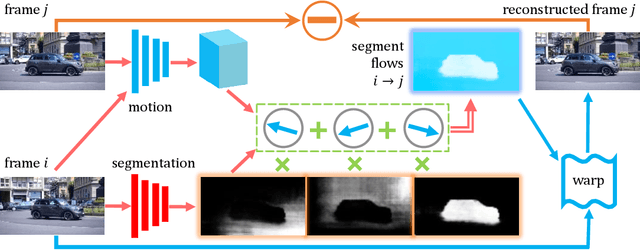

Humans can easily segment moving objects without knowing what they are. That objectness could emerge from continuous visual observations motivates us to model grouping and movement concurrently from unlabeled videos. Our premise is that a video has different views of the same scene related by moving components, and the right region segmentation and region flow would allow mutual view synthesis which can be checked from the data itself without any external supervision. Our model starts with two separate pathways: an appearance pathway that outputs feature-based region segmentation for a single image, and a motion pathway that outputs motion features for a pair of images. It then binds them in a conjoint representation called segment flow that pools flow offsets over each region and provides a gross characterization of moving regions for the entire scene. By training the model to minimize view synthesis errors based on segment flow, our appearance and motion pathways learn region segmentation and flow estimation automatically without building them up from low-level edges or optical flows respectively. Our model demonstrates the surprising emergence of objectness in the appearance pathway, surpassing prior works on zero-shot object segmentation from an image, moving object segmentation from a video with unsupervised test-time adaptation, and semantic image segmentation by supervised fine-tuning. Our work is the first truly end-to-end zero-shot object segmentation from videos. It not only develops generic objectness for segmentation and tracking, but also outperforms prevalent image-based contrastive learning methods without augmentation engineering.