 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effect of Data Augmentation on Classification of Atrial Fibrillation in Short Single-Lead ECG Signals Using Deep Neural Networks
Paper and Code
Feb 13, 2020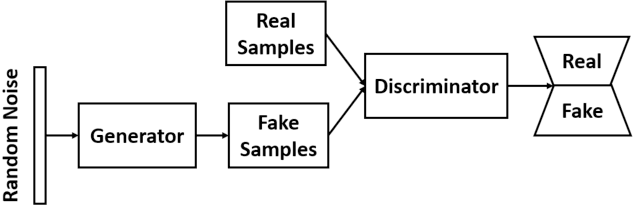


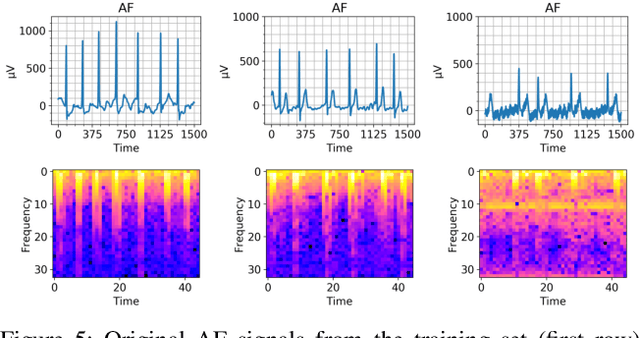
Cardiovascular diseases are the most common cause of mortality worldwide. Detection of atrial fibrillation (AF) in the asymptomatic stage can help prevent strokes. It also improves clinical decision making through the delivery of suitable treatment such as, anticoagulant therapy, in a timely manner. The clinical significance of such early detection of AF in electrocardiogram (ECG) signals has inspired numerous studies in recent years, of which many aim to solve this task by leveraging machine learning algorithms. ECG datasets containing AF samples, however, usually suffer from severe class imbalance, which if unaccounted for, affects the performance of classification algorithms. Data augmentation is a popular solution to tackle this problem. In this study, we investigate the impact of various data augmentation algorithms, e.g., oversampling, Gaussian Mixture Models (GMMs) and Generative Adversarial Networks (GANs), on solving the class imbalance problem. These algorithms are quantitatively and qualitatively evaluated, compared and discussed in detail. The results show that deep learning-based AF signal classification methods benefit more from data augmentation using GANs and GMMs, than oversampling. Furthermore, the GAN results in circa $3\%$ better AF classification accuracy in average while performing comparably to the GMM in terms of f1-score.