 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Difficulty of Passive Learning in Deep Reinforcement Learning
Paper and Code
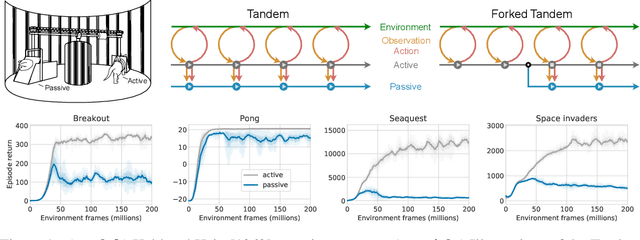

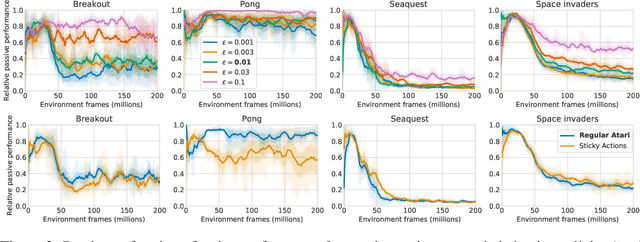

Learning to act from observational data without active environmental interaction is a well-known challenge in Reinforcement Learning (RL). Recent approaches involve constraints on the learned policy or conservative updates, preventing strong deviations from the state-action distribution of the dataset. Although these methods are evaluated using non-linear function approximation, theoretical justifications are mostly limited to the tabular or linear cases. Given the impressive results of deep reinforcement learning, we argue for a need to more clearly understand the challenges in this setting. In the vein of Held & Hein's classic 1963 experiment, we propose the "tandem learning" experimental paradigm which facilitates our empirical analysis of the difficulties in offline reinforcement learning. We identify function approximation in conjunction with fixed data distributions as the strongest factors, thereby extending but also challenging hypotheses stated in past work. Our results provide relevant insights for offline deep reinforcement learning, while also shedding new light on phenomena observed in the online case of learning control.