 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Curious Robot: Learning Visual Representations via Physical Interactions
Paper and Code
Jul 26, 2016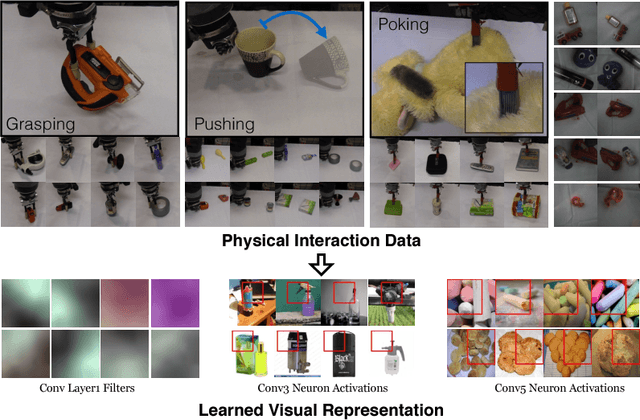



What is the right supervisory signal to train visual representations? Current approaches in computer vision use category labels from datasets such as ImageNet to train ConvNets. However, in case of biological agents, visual representation learning does not require millions of semantic labels. We argue that biological agents use physical interactions with the world to learn visual representations unlike current vision systems which just use passive observations (images and videos downloaded from web). For example, babies push objects, poke them, put them in their mouth and throw them to learn representations. Towards this goal, we build one of the first systems on a Baxter platform that pushes, pokes, grasps and observes objects in a tabletop environment. It uses four different types of physical interactions to collect more than 130K datapoints, with each datapoint providing supervision to a shared ConvNet architecture allowing us to learn visual representations. We show the quality of learned representations by observing neuron activations and performing nearest neighbor retrieval on this learned representation. Quantitatively, we evaluate our learned ConvNet on image classification tasks and show improvements compared to learning without external data. Finally, on the task of instance retrieval, our network outperforms the ImageNet network on recall@1 by 3%