 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Crucial Role of Normalization in Sharpness-Aware Minimization
Paper and Code
May 24, 2023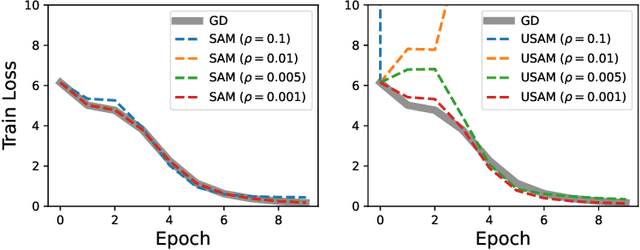



Sharpness-Aware Minimization (SAM) is a recently proposed gradient-based optimizer (Foret et al., ICLR 2021) that greatly improves the prediction performance of deep neural networks. Consequently, there has been a surge of interest in explaining its empirical success. We focus, in particular, on understanding the role played by normalization, a key component of the SAM updates. We theoretically and empirically study the effect of normalization in SAM for both convex and non-convex functions, revealing two key roles played by normalization: i) it helps in stabilizing the algorithm; and ii) it enables the algorithm to drift along a continuum (manifold) of minima -- a property identified by recent theoretical works that is the key to better performance. We further argue that these two properties of normalization make SAM robust against the choice of hyper-parameters, supporting the practicality of SAM. Our conclusions are backed by various experiments.