 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Blessings of Unlabeled Background in Untrimmed Videos
Paper and Code

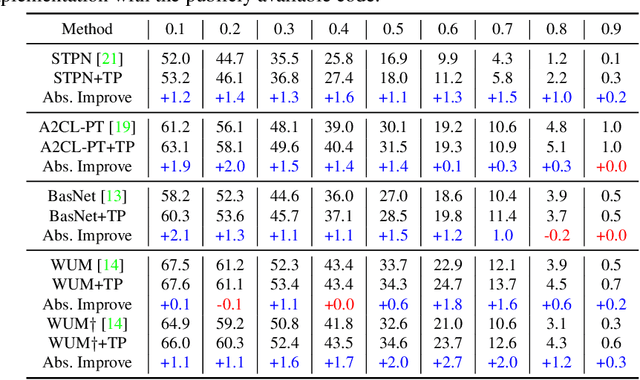

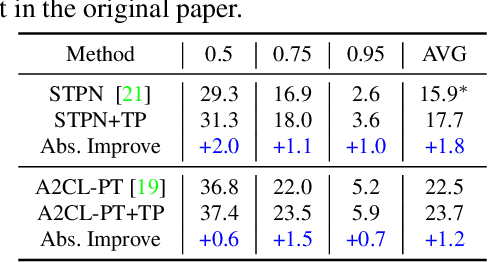
Weakly-supervised Temporal Action Localization (WTAL) aims to detect the action segments with only video-level action labels in training. The key challenge is how to distinguish the action of interest segments from the background, which is unlabelled even on the video-level. While previous works treat the background as "curses", we consider it as "blessings". Specifically, we first use causal analysis to point out that the common localization errors are due to the unobserved confounder that resides ubiquitously in visual recognition. Then, we propose a Temporal Smoothing PCA-based (TS-PCA) deconfounder, which exploits the unlabelled background to model an observed substitute for the unobserved confounder, to remove the confounding effect. Note that the proposed deconfounder is model-agnostic and non-intrusive, and hence can be applied in any WTAL method without model re-designs. Through extensive experiments on four state-of-the-art WTAL methods, we show that the deconfounder can improve all of them on the public datasets: THUMOS-14 and ActivityNet-1.3.