 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTF-Attention-Net: An End To End Neural Network For Singing Voice Separation
Paper and Code
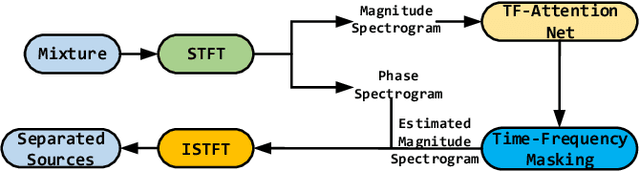
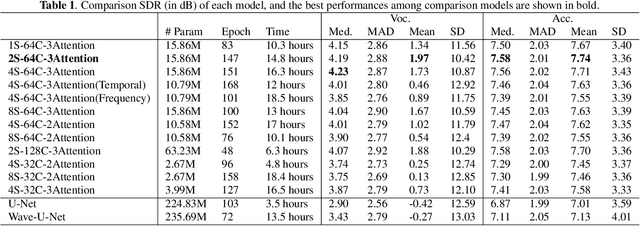
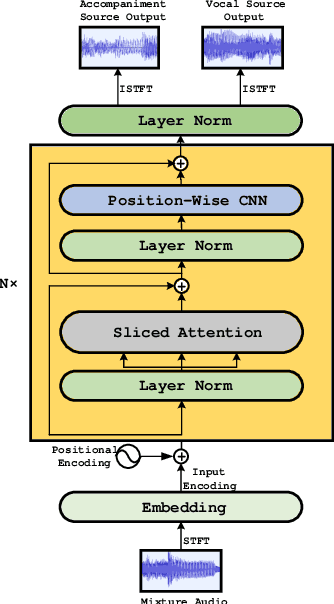
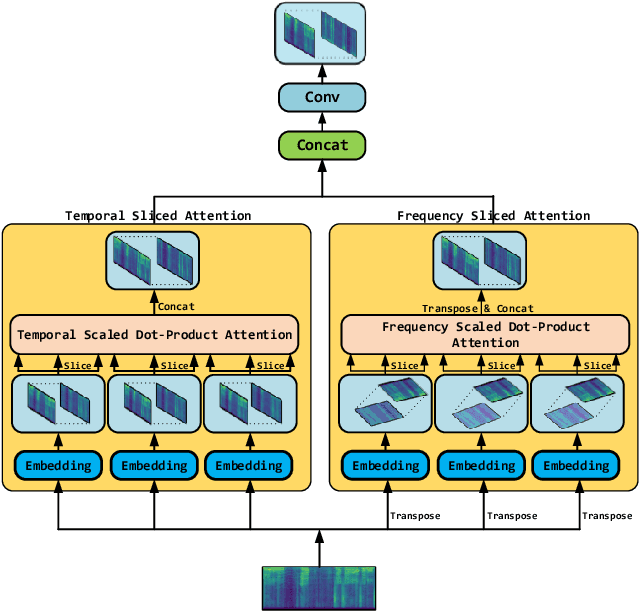
In terms of source separation task, deep neural networks have two major approaches: one approach is modeling in the spectrogram domain, and the other approach is modeling in the waveform domain. Most of the previous papers use CNNs or LSTMs. However, due to the high sampling rate of audio, whether it is LSTMs with long-distance dependent or CNNs with sliding windows, it is still difficult to extract long-term input context. In this case, we propose an end-to-end network: Time-Frequency Attention Net (TF-Attention-Net), to study the ability of the attention mechanism in the source separation task. First, we introduce the Slice Attention, which can extract the acoustic features of temporal and frequency scales under different channels. Besides, the attention mechanism can be parallel calculated, while LSTMs cannot, because of its time-dependent property. Meanwhile, the receptive field of the attention mechanism is larger than the CNNs, which means that we can use shallower layers to extract longer distance dependence. Experiments indicate that our proposed TF-Attention-Net outperforms both the spectrogram-based U-Net and the waveform-based Wave-U-Net baselines.