 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTENT: Text Classification Based on ENcoding Tree Learning
Paper and Code
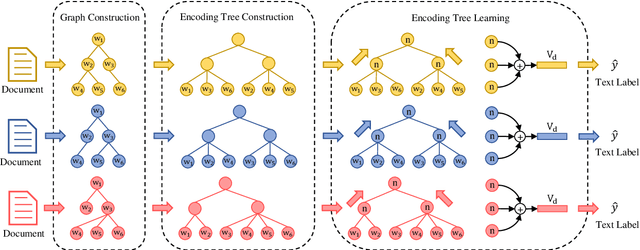
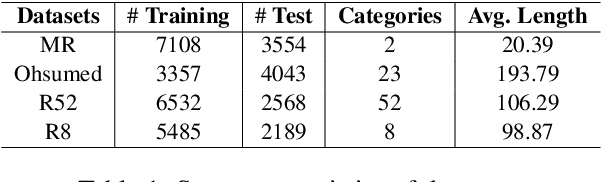
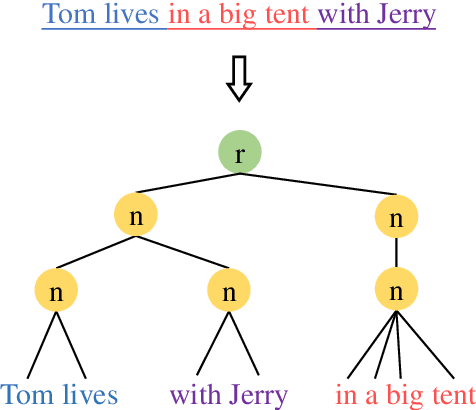
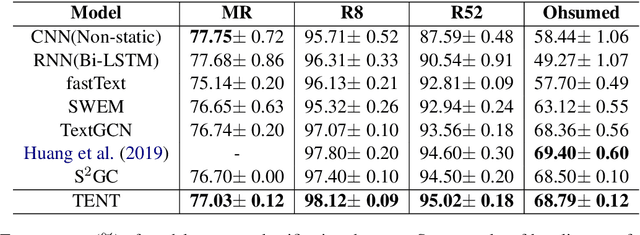
Text classification is a primary task in natural language processing (NLP). Recently, graph neural networks (GNNs) have developed rapidly and been applied to text classification tasks. Although more complex models tend to achieve better performance, research highly depends on the computing power of the device used. In this article, we propose TENT (https://github.com/Daisean/TENT) to obtain better text classification performance and reduce the reliance on computing power. Specifically, we first establish a dependency analysis graph for each text and then convert each graph into its corresponding encoding tree. The representation of the entire graph is obtained by updating the representation of the non-leaf nodes in the encoding tree. Experimental results show that our method outperforms other baselines on several datasets while having a simple structure and few parameters.