 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTencent's Multilingual Machine Translation System for WMT22 Large-Scale African Languages
Paper and Code

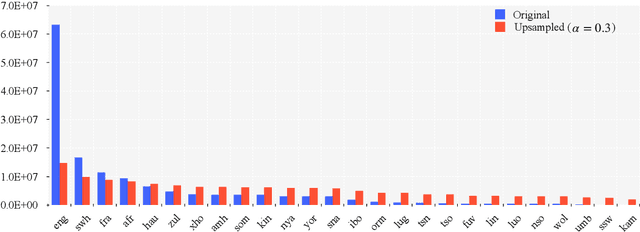


This paper describes Tencent's multilingual machine translation systems for the WMT22 shared task on Large-Scale Machine Translation Evaluation for African Languages. We participated in the $\mathbf{constrained}$ translation track in which only the data and pretrained models provided by the organizer are allowed. The task is challenging due to three problems, including the absence of training data for some to-be-evaluated language pairs, the uneven optimization of language pairs caused by data imbalance, and the curse of multilinguality. To address these problems, we adopt data augmentation, distributionally robust optimization, and language family grouping, respectively, to develop our multilingual neural machine translation (MNMT) models. Our submissions won the $\mathbf{1st\ place}$ on the blind test sets in terms of the automatic evaluation metrics. Codes, models, and detailed competition results are available at https://github.com/wxjiao/WMT2022-Large-Scale-African.