 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporally Coherent GANs for Video Super-Resolution (TecoGAN)
Paper and Code
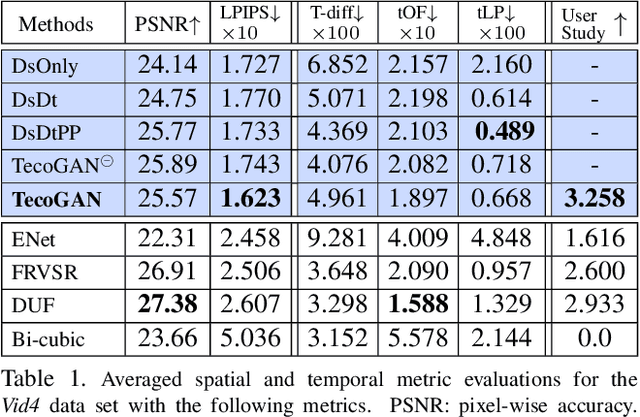

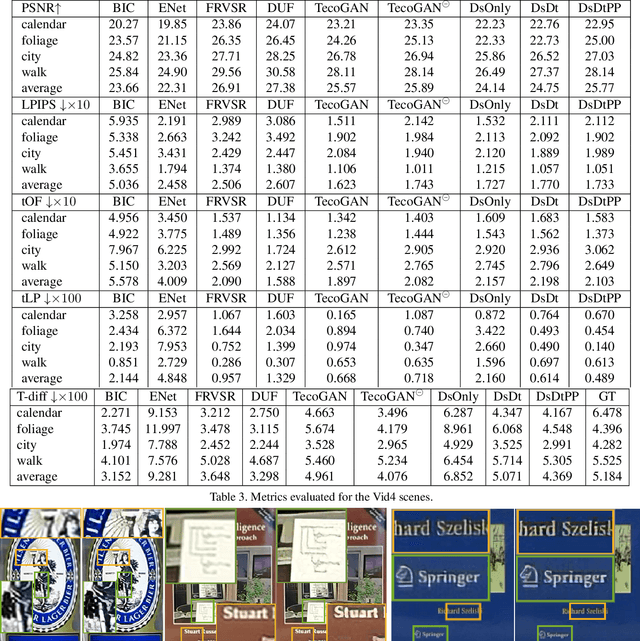

Adversarial training has been highly successful in the context of image super-resolution. It was demonstrated to yield realistic and highly detailed results. Despite this success, many state-of-the-art methods for video super-resolution still favor simpler norms such as $L_2$ over adversarial loss functions. This is caused by the fact that the averaging nature of direct vector norms as loss functions leads to temporal smoothness. The lack of spatial detail means temporal coherence is easily established. In our work, we instead propose an adversarial training for video super-resolution that leads to temporally coherent solutions without sacrificing spatial detail. In our generator, we use a recurrent, residual framework that naturally encourages temporal consistency. For adversarial training, we propose a novel spatio-temporal discriminator in combination with motion compensation to guarantee photo-realistic and temporally coherent details in the results. We additionally identify a class of temporal artifacts in these recurrent networks, and propose a novel Ping-Pong loss to remove them. Quantifying the temporal coherence for image super-resolution tasks has also not been addressed previously. We propose a first set of metrics to evaluate the accuracy as well as the perceptual quality of the temporal evolution, and we demonstrate that our method outperforms previous work by yielding realistic and detailed images with natural temporal changes.