 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal 3D ConvNets: New Architecture and Transfer Learning for Video Classification
Paper and Code
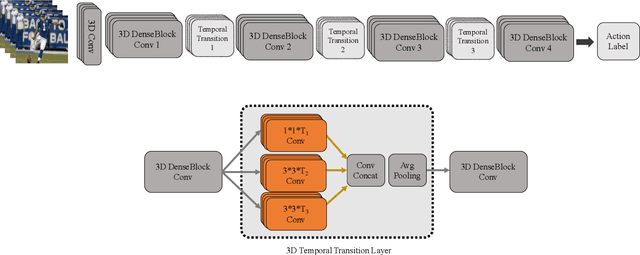



The work in this paper is driven by the question how to exploit the temporal cues available in videos for their accurate classification, and for human action recognition in particular? Thus far, the vision community has focused on spatio-temporal approaches with fixed temporal convolution kernel depths. We introduce a new temporal layer that models variable temporal convolution kernel depths. We embed this new temporal layer in our proposed 3D CNN. We extend the DenseNet architecture - which normally is 2D - with 3D filters and pooling kernels. We name our proposed video convolutional network `Temporal 3D ConvNet'~(T3D) and its new temporal layer `Temporal Transition Layer'~(TTL). Our experiments show that T3D outperforms the current state-of-the-art methods on the HMDB51, UCF101 and Kinetics datasets. The other issue in training 3D ConvNets is about training them from scratch with a huge labeled dataset to get a reasonable performance. So the knowledge learned in 2D ConvNets is completely ignored. Another contribution in this work is a simple and effective technique to transfer knowledge from a pre-trained 2D CNN to a randomly initialized 3D CNN for a stable weight initialization. This allows us to significantly reduce the number of training samples for 3D CNNs. Thus, by finetuning this network, we beat the performance of generic and recent methods in 3D CNNs, which were trained on large video datasets, e.g. Sports-1M, and finetuned on the target datasets, e.g. HMDB51/UCF101. The T3D codes will be released