 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTCAM: Temporal Class Activation Maps for Object Localization in Weakly-Labeled Unconstrained Videos
Paper and Code
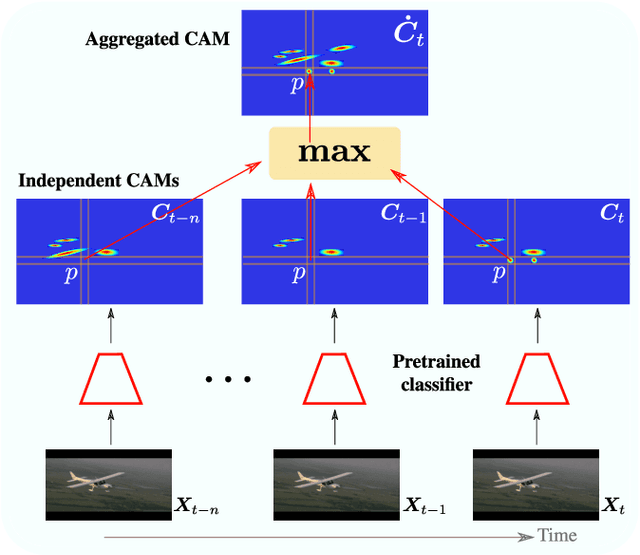
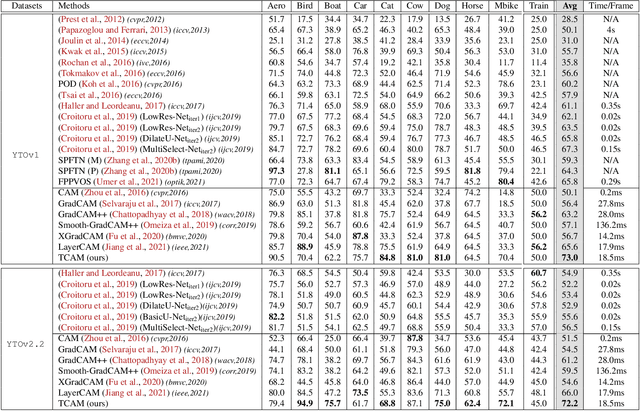
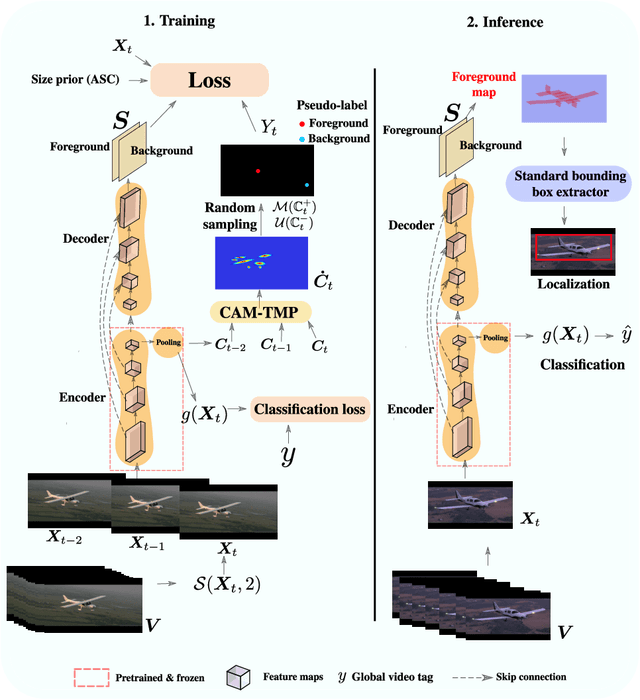
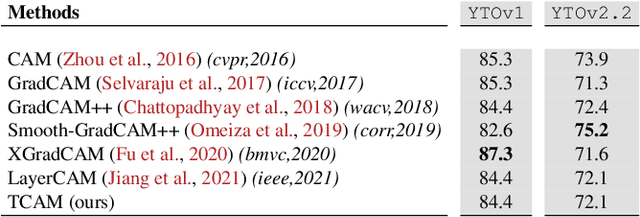
Weakly supervised video object localization (WSVOL) allows locating object in videos using only global video tags such as object class. State-of-art methods rely on multiple independent stages, where initial spatio-temporal proposals are generated using visual and motion cues, then prominent objects are identified and refined. Localization is done by solving an optimization problem over one or more videos, and video tags are typically used for video clustering. This requires a model per-video or per-class making for costly inference. Moreover, localized regions are not necessary discriminant because of unsupervised motion methods like optical flow, or because video tags are discarded from optimization. In this paper, we leverage the successful class activation mapping (CAM) methods, designed for WSOL based on still images. A new Temporal CAM (TCAM) method is introduced to train a discriminant deep learning (DL) model to exploit spatio-temporal information in videos, using an aggregation mechanism, called CAM-Temporal Max Pooling (CAM-TMP), over consecutive CAMs. In particular, activations of regions of interest (ROIs) are collected from CAMs produced by a pretrained CNN classifier to build pixel-wise pseudo-labels for training the DL model. In addition, a global unsupervised size constraint, and local constraint such as CRF are used to yield more accurate CAMs. Inference over single independent frames allows parallel processing of a clip of frames, and real-time localization. Extensive experiments on two challenging YouTube-Objects datasets for unconstrained videos, indicate that CAM methods (trained on independent frames) can yield decent localization accuracy. Our proposed TCAM method achieves a new state-of-art in WSVOL accuracy, and visual results suggest that it can be adapted for subsequent tasks like visual object tracking and detection. Code is publicly available.