 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Oriented Multi-User Semantic Communications
Paper and Code
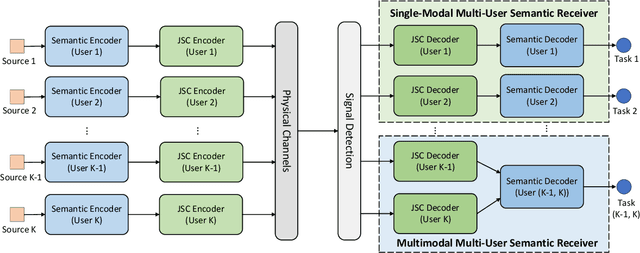


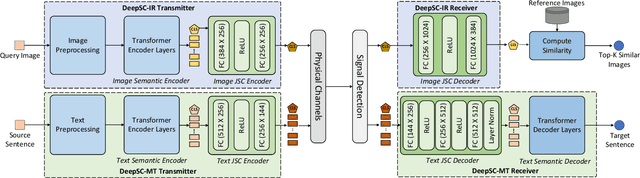
While semantic communications have shown the potential in the case of single-modal single-users, its applications to the multi-user scenario remain limited. In this paper, we investigate deep learning (DL) based multi-user semantic communication systems for transmitting single-modal data and multimodal data, respectively. We will adopt three intelligent tasks, including, image retrieval, machine translation, and visual question answering (VQA) as the transmission goal of semantic communication systems. We will then propose a Transformer based unique framework to unify the structure of transmitters for different tasks. For the single-modal multi-user system, we will propose two Transformer based models, named, DeepSC-IR and DeepSC-MT, to perform image retrieval and machine translation, respectively. In this case, DeepSC-IR is trained to optimize the distance in embedding space between images and DeepSC-MT is trained to minimize the semantic errors by recovering the semantic meaning of sentences. For the multimodal multi-user system, we develop a Transformer enabled model, named, DeepSC-VQA, for the VQA task by extracting text-image information at the transmitters and fusing it at the receiver. In particular, a novel layer-wise Transformer is designed to help fuse multimodal data by adding connection between each of the encoder and decoder layers. Numerical results will show that the proposed models are superior to traditional communications in terms of the robustness to channels, computational complexity, transmission delay, and the task-execution performance at various task-specific metrics.