 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Adaptive Pre-Training for Boosting Learning With Noisy Labels: A Study on Text Classification for African Languages
Paper and Code
Jun 03, 2022
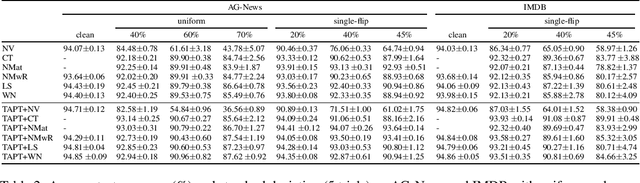
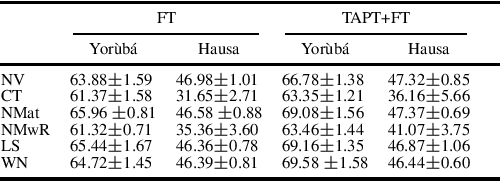
For high-resource languages like English, text classification is a well-studied task. The performance of modern NLP models easily achieves an accuracy of more than 90% in many standard datasets for text classification in English (Xie et al., 2019; Yang et al., 2019; Zaheer et al., 2020). However, text classification in low-resource languages is still challenging due to the lack of annotated data. Although methods like weak supervision and crowdsourcing can help ease the annotation bottleneck, the annotations obtained by these methods contain label noise. Models trained with label noise may not generalize well. To this end, a variety of noise-handling techniques have been proposed to alleviate the negative impact caused by the errors in the annotations (for extensive surveys see (Hedderich et al., 2021; Algan & Ulusoy, 2021)). In this work, we experiment with a group of standard noisy-handling methods on text classification tasks with noisy labels. We study both simulated noise and realistic noise induced by weak supervision. Moreover, we find task-adaptive pre-training techniques (Gururangan et al., 2020) are beneficial for learning with noisy labels.